COCO-FUNIT: Few-Shot Unsupervised Image Translation
with a Content Conditioned Style Encoder
Kuniaki Saito1, 2 Kate Saenko1 Ming-Yu Liu2
1. Boston University 2. NVIDIA
in ECCV 2020 (Spotlight)
Paper | Code | Demo Video | 10-min Video

Abstract
Unsupervised image-to-image translation intends to learn a mapping of an image in a given domain to an analogous image in a different domain, without explicit supervision of the mapping. Few-shot unsupervised image-to-image translation further attempts to generalize the model to an unseen domain by leveraging example images of the unseen domain provided at inference time. While remarkably successful, existing few-shot image-to-image translation models find it difficult to preserve the structure of the input image while emulating the appearance of the unseen domain, which we refer to as the content loss problem. This is particularly severe when the poses of the objects in the input and example images are very different. To address the issue, we propose a new few-shot image translation model, which computes the style embedding of the example images conditioned on the input image and a new architecture design called the universal style bias. Through extensive experimental validations with comparison to the state-of-the-art, our model shows effectiveness in addressing the content loss problem.

Paper
arxiv, 2020.
Citation
Kuniaki Saito, Kate Saenko, Ming-Yu Liu.
"COCO-FUNIT: Few-Shot Unsupervised Image Translation with a Content Conditioned Style Encoder", in ECCV, 2020.
Bibtex
Code
Summary Video |
Few shot unsupervised image-to-image translation

Generating images in unseen domain is a challenging problem. To solve the task, few-shot unsupervised image-to-image translation framework (Liu et. al.) leveraged example-guided episodic training and generated realistic images from unseen domains given a few reference images.
Content Loss Problem

However, their framework is limited in one aspect. The few-shot translation framework frequently generates unsatisfactory translation outputs when the model is applied to objects with diverse appearance, such as animals with very different body poses. The domain invariant content that is supposed to remain unchanged disappears after translation, as shown above. We will call this issue the content loss problem.
Content Conditioned Style Encoder
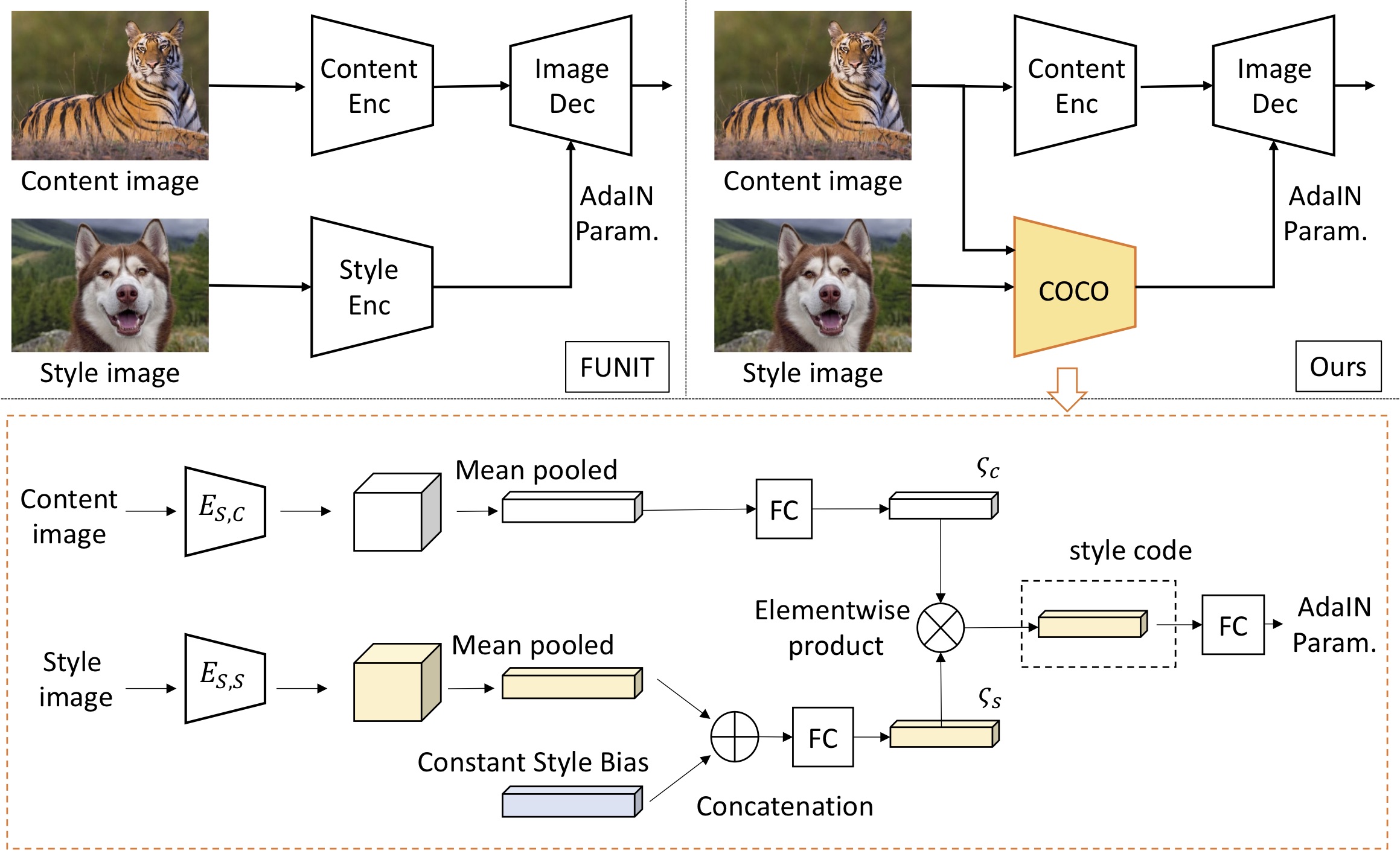
We propose a novel network architecture to solve the content loss problem. We design a style encoder called the content-conditioned style encoder to hinder the transmission of task-irrelevant appearance information to the image translation process. In contrast to the existing style encoders, our style code is computed by conditioning on the input content image. We use a new architecture design to limit the variance of the style code.
Few-shot Image-to-Image Translation Examples
We show results on Carnivorous, bird, and mammal translation. For each example,



Comparison with FUNIT
We show comparison with FUNIT on animal-face translation. Our architecture achieves photo-realistic translation.

Style Blending Examples
We show results on blending style of two images. S1 and S2 are style images and we take a linear interporation of their style embeddings.
