Few-Shot Unsupervised Image-to-Image Translation
Ming-Yu Liu Xun Huang Arun Mallya Tero Karras Timo Aila Jaakko Lehtinen Jan Kautz
NVIDIA
in ICCV 2019
Paper | Code | Demo
Abstract
Unsupervised image-to-image translation methods learn to map images in a given class to an analogous image in a different class, drawing on unstructured (non-registered) datasets of images. While remarkably successful, current methods require access to many images in both source and destination classes at training time. We argue this greatly limits their use. Drawing inspiration from the human capability of picking up the essence of a novel object from a small number of examples and generalizing from there, we seek a few-shot, unsupervised image-to-image translation algorithm that works on previously unseen target classes that are specified, at test time, only by a few example images. Our model achieves this few-shot generation capability by coupling an adversarial training scheme with a novel network design. Through extensive experimental validation and comparisons to several baseline methods on benchmark datasets, we verify the effectiveness of the proposed framework.

Paper
arxiv, 2019.
Citation
Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, and Jan Kautz.
"Few-shot Unsupervised Image-to-Image Translation", in ICCV, 2019.
Bibtex
Code
FUNIT Explained |
GANimal Demo |
Problem Setting
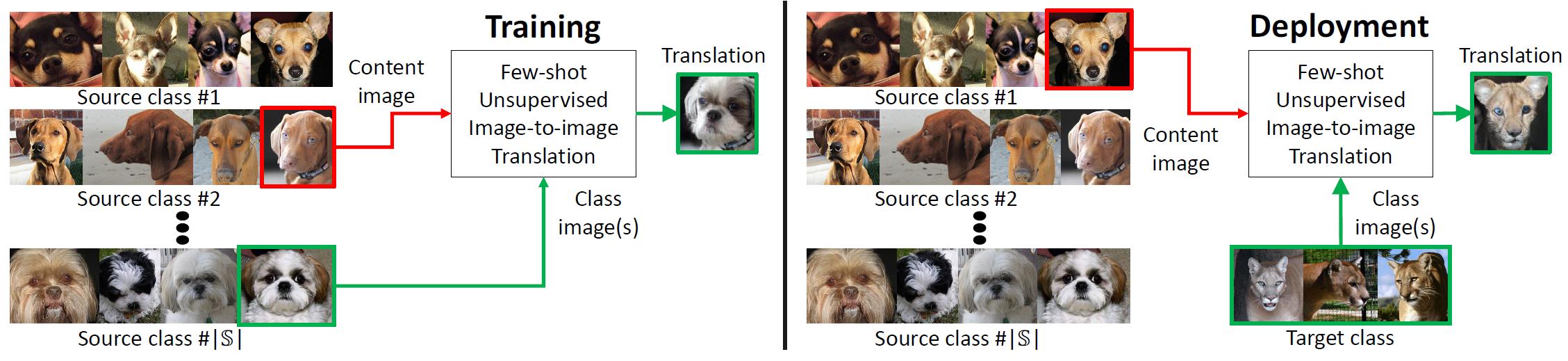
While unsupervised/unpaired image-to-image translation methods (e.g., Liu and Tuzel, Liu et. al., Zhu et. al., and Huang et. al.) have achieved remarkable success, they are still limited in two aspects.
We propose a few-shot unsupervised image-to-image translation framework (FUNIT) to address the limitation. In the training time, the FUNIT model learns to translate images between any two classes sampled from a set of source classes. In the test time, the model is presented a few images of a target class that the model has never seen before. The model leverages these few example images to translate an input image of a source class to the target class.
Few-shot Unsupervised Image-to-Image Translation Examples
We show results on animal face translation, bird translation, flower translation, and food translation. For each example,
Our model is able to translate a leopard to a sharpei even though it has never seen a single image of a sharpei in the training time.
