We present FoundationPose, a unified foundation model for 6D object pose estimation and tracking, supporting both model-based and model-free setups. Our approach can be instantly applied at test-time to a novel object without fine-tuning, as long as its CAD model is given, or a small number of reference images are captured. We bridge the gap between these two setups with a neural implicit representation that allows for effective novel view synthesis, keeping the downstream pose estimation modules invariant under the same unified framework. Strong generalizability is achieved via large-scale synthetic training, aided by a large language model (LLM), a novel transformer-based architecture, and contrastive learning formulation. Extensive evaluation on multiple public datasets involving challenging scenarios and objects indicate our unified approach outperforms existing methods specialized for each task by a large margin. In addition, it even achieves comparable results to instance-level methods despite the reduced assumptions.
We produce high quality pose results even comparable with the ground truth.
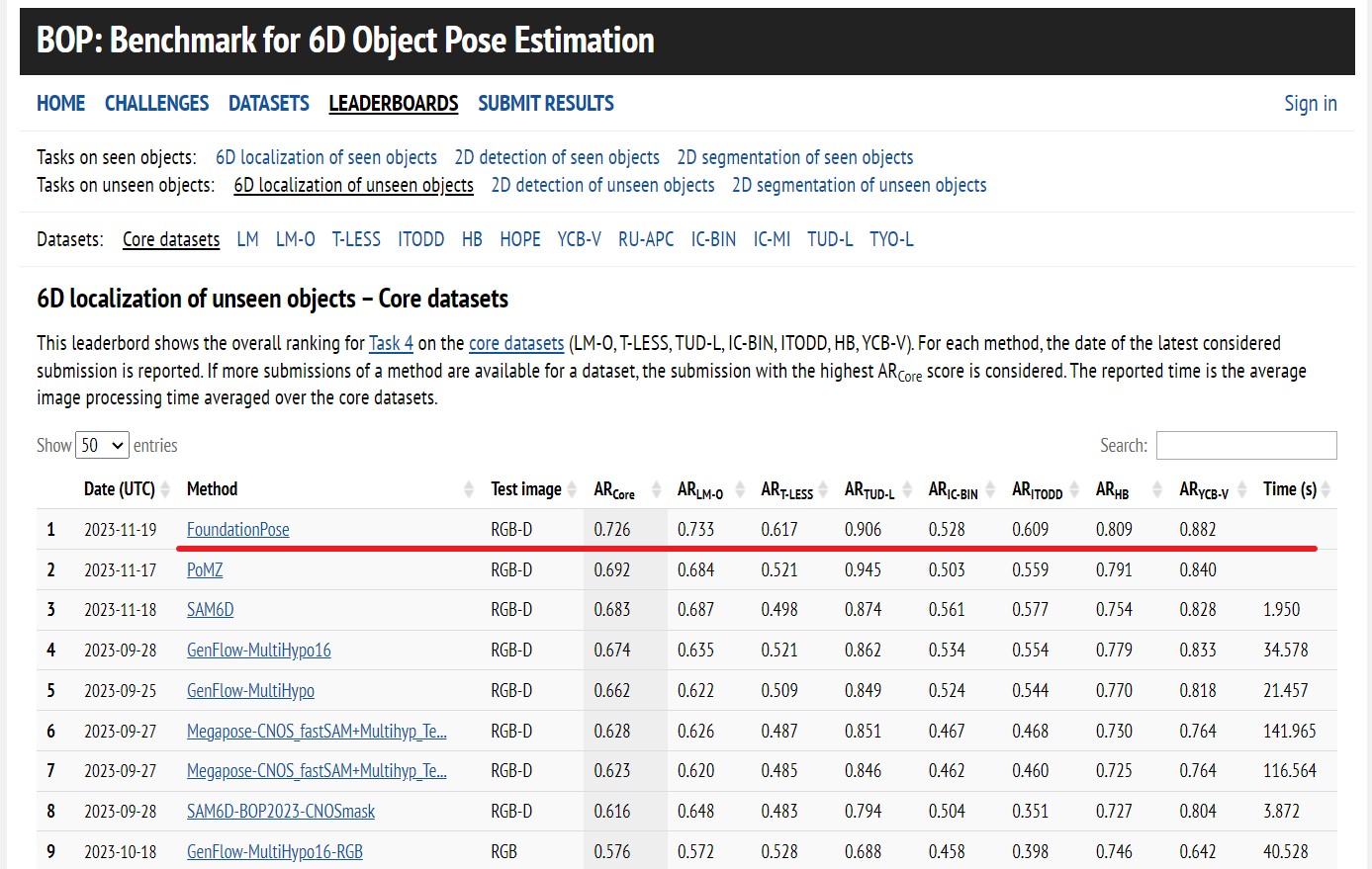
We obtained the 1st place on the BOP leaderboard for model-based novel object pose estimation.
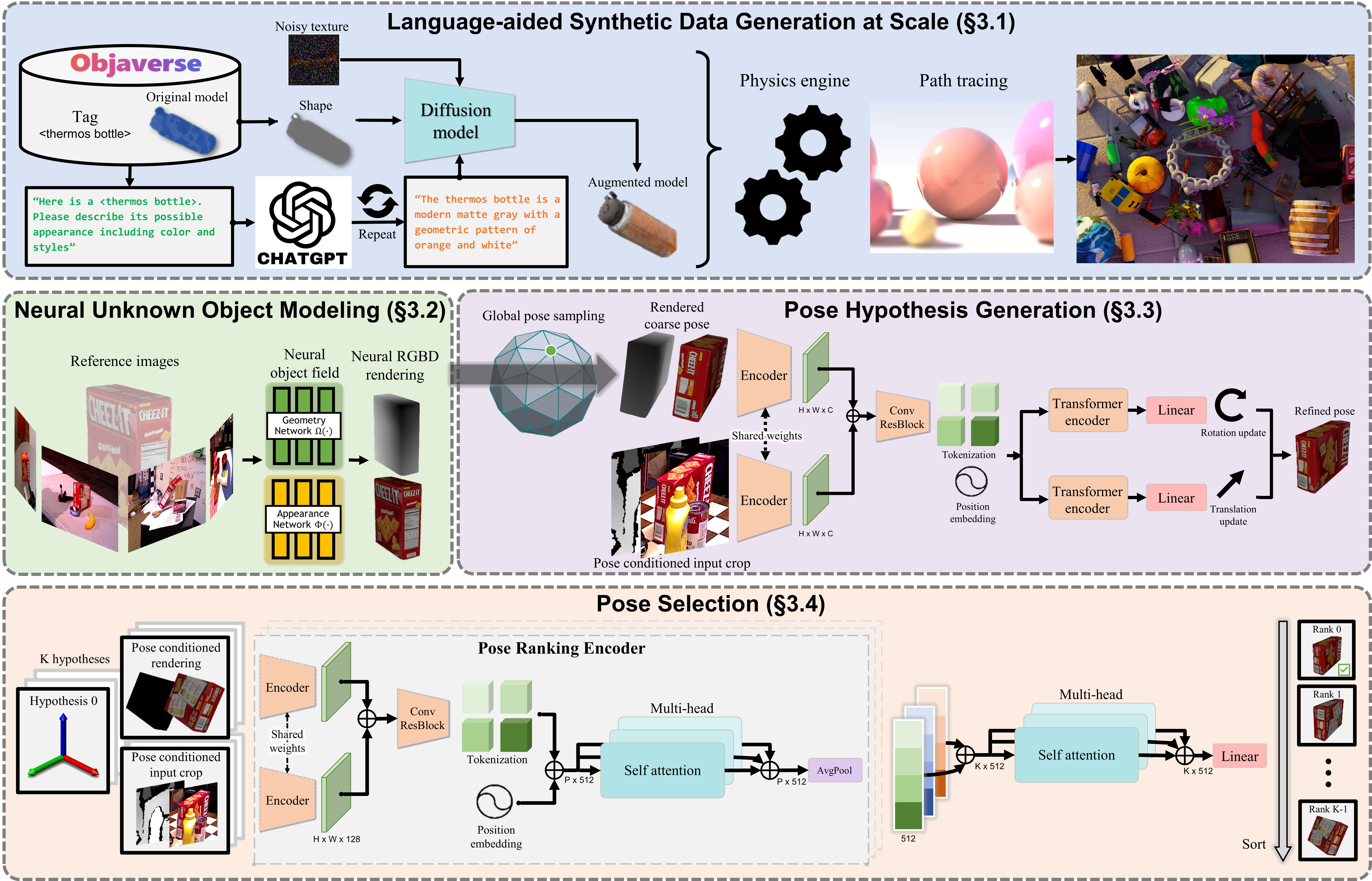
To reduce manual efforts for large scale training, we developed a novel synthetic data generation pipeline by leveraging recent emerging techniques and resources including 3D model database, large language models and diffusion models (Sec. 3.1). To bridge the gap between model-free and model-based setup, we leverage an object-centric neural field (Sec. 3.2) for novel view RGBD rendering for subsequent render-and-compare. For pose estimation, we first initialize global poses uniformly around the object, which are then refined by the refinement network (Sec. 3.3). Finally, we forward the refined poses to the pose selection module which predicts their scores. The pose with the best score is selected as output (Sec. 3.4).