Abstract
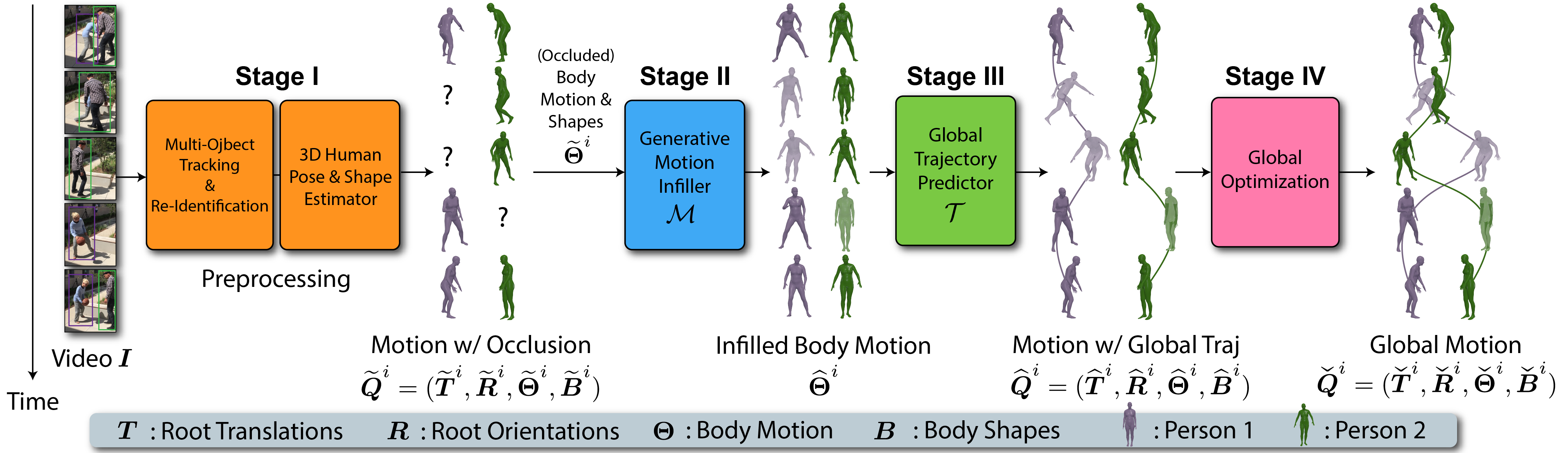
We present an approach for 3D global human mesh recovery from monocular videos recorded with dynamic cameras. Our approach is robust to severe and long-term occlusions and tracks human bodies even when they go outside the camera's field of view. To achieve this, we first propose a deep generative motion infiller, which autoregressively infills the body motions of occluded humans based on visible motions. Additionally, in contrast to prior work, our approach reconstructs human meshes in consistent global coordinates even with dynamic cameras. Since the joint reconstruction of human motions and camera poses is underconstrained, we propose a global trajectory predictor that generates global human trajectories based on local body movements. Using the predicted trajectories as anchors, we present a global optimization framework that refines the predicted trajectories and optimizes the camera poses to match the video evidence such as 2D keypoints. Experiments on challenging indoor and in-the-wild datasets with dynamic cameras demonstrate that the proposed approach outperforms prior methods significantly in terms of motion infilling and global mesh recovery.
Results
In-The-Wild Videos with Dynamic Cameras (vs. SOTA HybrIK)
In-The-Wild Videos with Static Cameras (vs. SOTA HybrIK)
Generative Motion Infilling with Multiple Samples
3DPW Sequences
Narrated Results Video
Overview
Citation
@inproceedings{yuan2022glamr,
title={GLAMR: Global Occlusion-Aware Human Mesh Recovery with Dynamic Cameras},
author={Yuan, Ye and Iqbal, Umar and Molchanov, Pavlo and Kitani, Kris and Kautz, Jan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}