LongLive: Real-time Interactive Long Video Generation¶
LongLive: Real-time Interactive Long Video Generation [Paper]
Shuai Yang,
Wei Huang,
Ruihang Chu,
Yicheng Xiao,
Yuyang Zhao,
Xianbang Wang,
Muyang Li,
Enze Xie,
Yingcong Chen,
Yao Lu,
Song Han,
Yukang Chen
📽️ About LongLive¶
We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training.In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions.
To address these challenges, LongLive adopts a causal, frame-level AR design that integrates:
- KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches;
- Streaming long tuning to enable long video training and to align training and inference (train-long-test-long);
- Short window attention paired with a frame-level attention sink, shortened as frame sink, preserving long-range consistency while enabling faster generation.
With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
Introduction

LongLive accepts sequential user prompts and generates corresponding videos in real time, enabling user-guided long video generation.
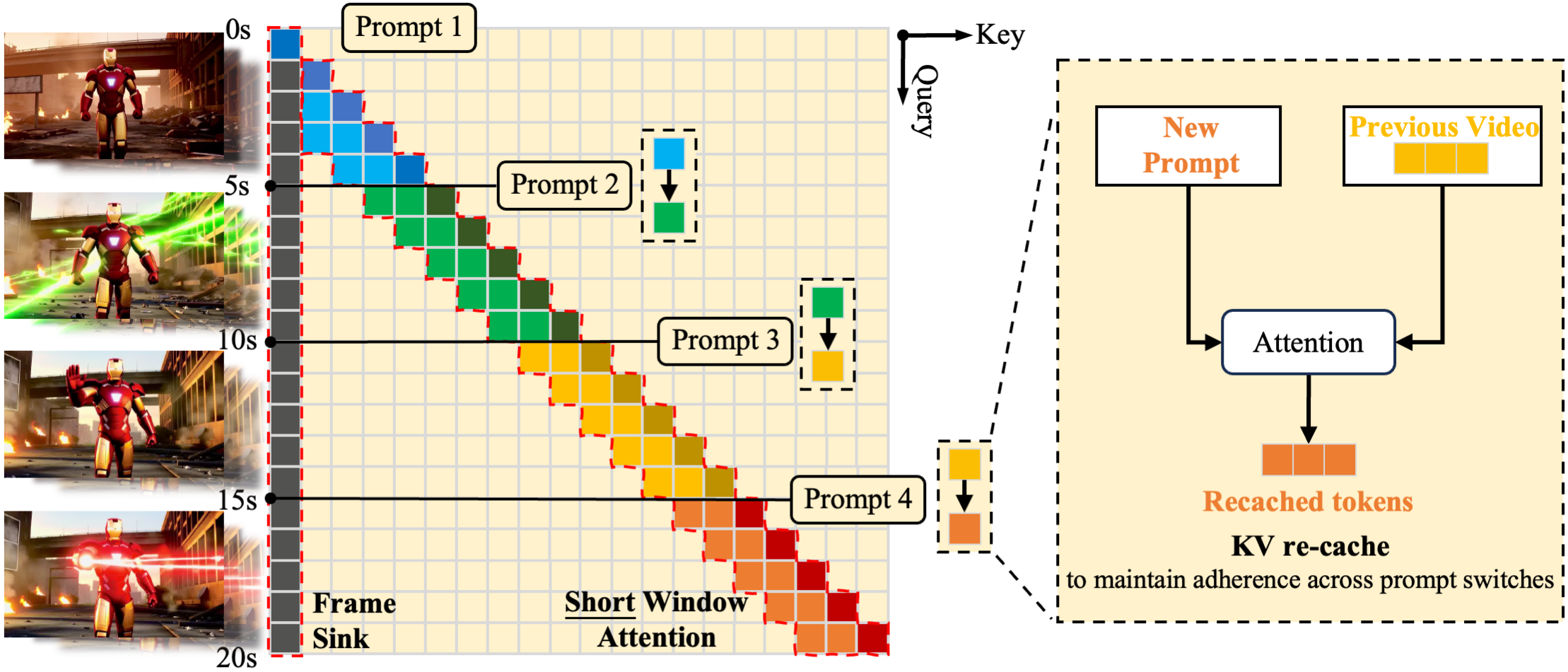
The framework of LongLive. (Left) Frame Sink + Short window attention. (Right) KV-recache.
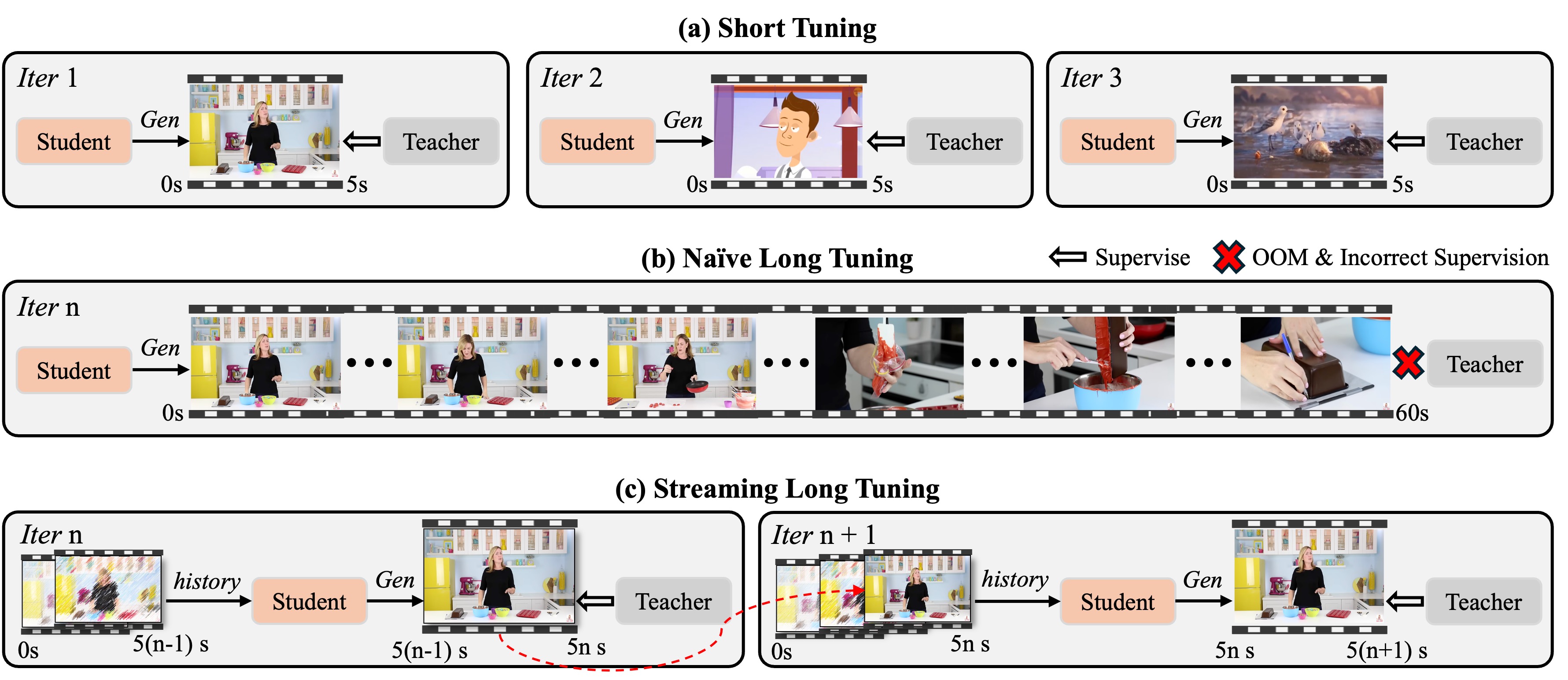
The streaming long tuning pipeline. Our approach trains on long sequences by reusing the historical KV cache each iteration to generate the next 5s clip, then supervising it with the teacher.
Installation
Requirements
We tested this repo on the following setup:
- Nvidia GPU with at least 40 GB memory (A100, and H100 are tested).
- Linux operating system.
- 64 GB RAM.
Other hardware setup could also work but hasn't been tested.
Environment
Create a conda environment and install dependencies:
git clone https://github.com/NVlabs/LongLive
cd LongLive
conda create -n longlive python=3.10 -y
conda activate longlive
conda install nvidia/label/cuda-12.4.1::cuda
conda install -c nvidia/label/cuda-12.4.1 cudatoolkit
pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu128
pip install -r requirements.txt
pip install flash-attn --no-build-isolationInference
Download checkpoints
huggingface-cli download Wan-AI/Wan2.1-T2V-1.3B --local-dir wan_models/Wan2.1-T2V-1.3B
huggingface-cli download Efficient-Large-Model/LongLive --local-dir longlive_modelsSingle Prompt Video Generation
bash inference.shInteractive Long Video Generation
bash interactive_inference.shHints for video prompt
- When building interactive prompts, include a brief subject (who/what) and background/setting (where) in every prompt. Re-stating these anchors at each step greatly improves global coherence during prompt switches. See the
examplefor the exact prompt set we used to produce some of our videos on the demo page. - LongLive supports diverse interaction—action changes, introducing/removing objects, background shifts, style changes, and more. But during large scene transitions the camera motion cannot be explicitly controlled. In another word, LongLive excels at cinematic long takes, but is less suited to rapid shot-by-shot edits or fast cutscenes.
Training
Download checkpoints
Please follow Self-Forcing to download text prompts and ODE initialized checkpoint. Download Wan2.1-T2V-14B as the teacher model.
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir wan_models/Wan2.1-T2V-14BStep1: Self-Forcing Initialization for Short Window and Frame Sink
bash train_init.shStep2: Streaming Long Tuning
bash train_long.shCitation
Please consider to cite our paper and this framework, if they are helpful in your research.
@article{yang2025longlive,
title={LongLive: Real-time Interactive Long Video Generation},
author={Shuai Yang and Wei Huang and Ruihang Chu and Yicheng Xiao and Yuyang Zhao and Xianbang Wang and Muyang Li and Enze Xie and Yingcong Chen and Yao Lu and Song Han and Yukang Chen},
year={2025},
eprint={2509.22622},
archivePrefix={arXiv},
primaryClass={cs.CV}
}License
Apache 2.0
Acknowledgement
- Self-Forcing: the codebase and algorithm we built upon. Thanks for their wonderful work.
- Wan: the base model we built upon. Thanks for their wonderful work.