Exploring the Next Generation of Data
in the Era of Foundation Models
Recording of the tutorial and workshop on YouTube will be available to the general public once the 3-month embargo lifts.
[March 2025] We are hosting a CVPR 2025 Workshop NeXD. Join us! [March 2025] We are hosting a CVPR 2025 Tutorial VAST, please stop by and participate!
Our Mission
Data has become more pivotal than ever, driving advancements from the first generation of deep learning models to the emergence of foundation models. The significant momentum behind foundation models has spurred their continuous integration into various applications, such as autonomous driving, medical diagnostics, and AI-powered chatbots. To ensure reliable and safe model development, the quality of the massive datasets these models depend on has gained increasing interest and attention. Given the sheer scale of raw data, it is essential to develop scalable methods to evaluate and select data based on the data quality and relevance to both general and specific tasks. Furthermore, foundation models themselves are now utilized to understand and uncover more data for further training, creating a feedback loop between models and datasets.
Our ultimate goal is to tackle this enormous challenge surrounding the next generation of data from numerous angles. In our trials, we consider several factors: definitions of quality data, bias-free data, scalability, generating data, ethical data gathering, continuous data gathering, and hallucination-free foundation models for data mining.
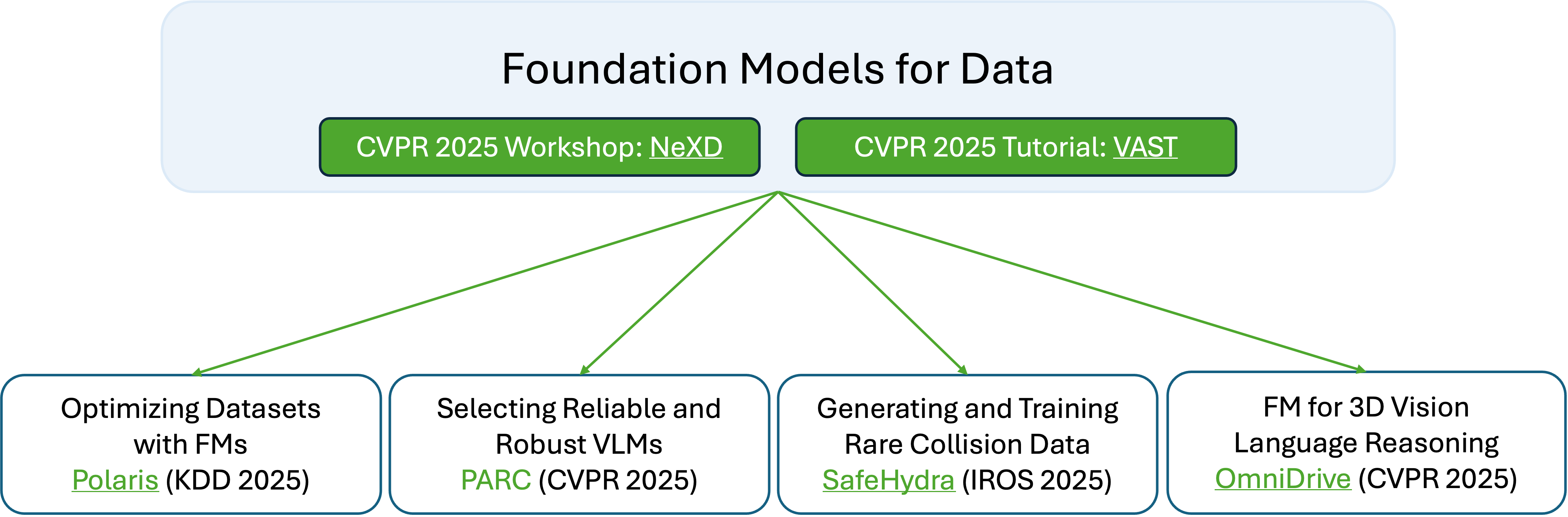
Today, we have started tackling this behemoth challenge through 4 different directions, with more in the works!
- Polaris (KDD 2025): We optimize training datasets by leveraging foundation models.
- PARC (CVPR 2025): We introduce a framework which can select the most reliable and robust vision-language models (VLMs).
- SafeHydra (IROS 2025): We generate rare collision cases and successfully integrate them into training with foundation models for safety critical application, autonomous driving.
- OmniDrive (CVPR 2025): We create a dataset and strong foundation model baselines that perform 3D vision-language reasoning for safety critical application, autonomous driving.
More details on the papers and their respective webpages are available below.
Our Works
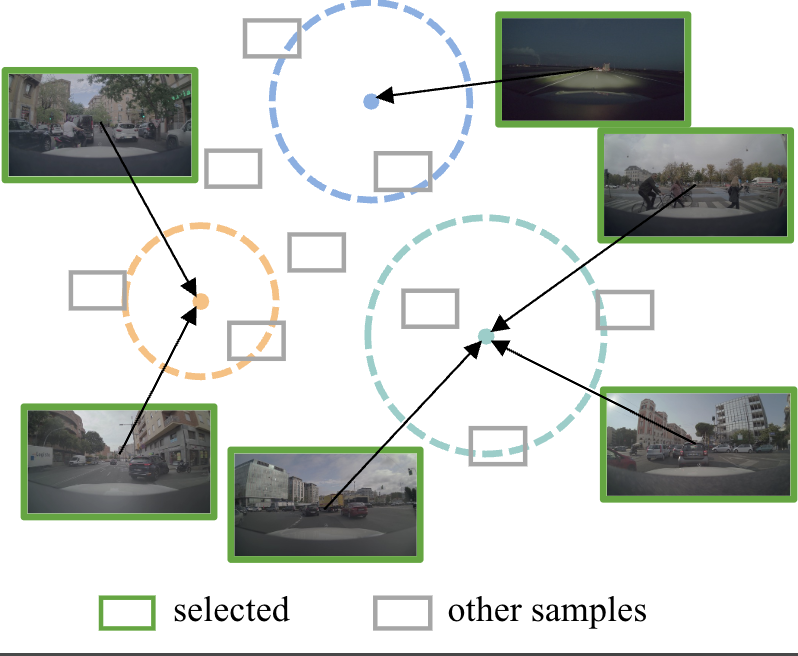
Maying Shen*, Nadine Chang*, Sifei Liu, Jose M. Alvarez
KDD 2025
Paper and code coming soon!
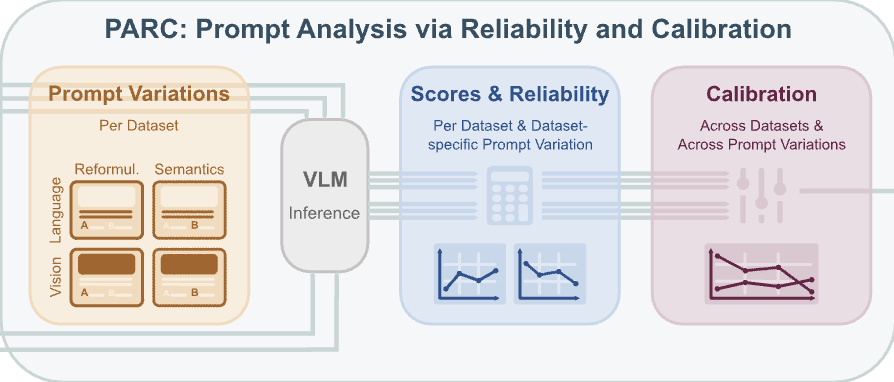
Jenny Schmalfuss, Nadine Chang, Vibashan VS, Maying Shen, Andres Bruhn, Jose M. Alvarez
CVPR 2025
Paper / Code
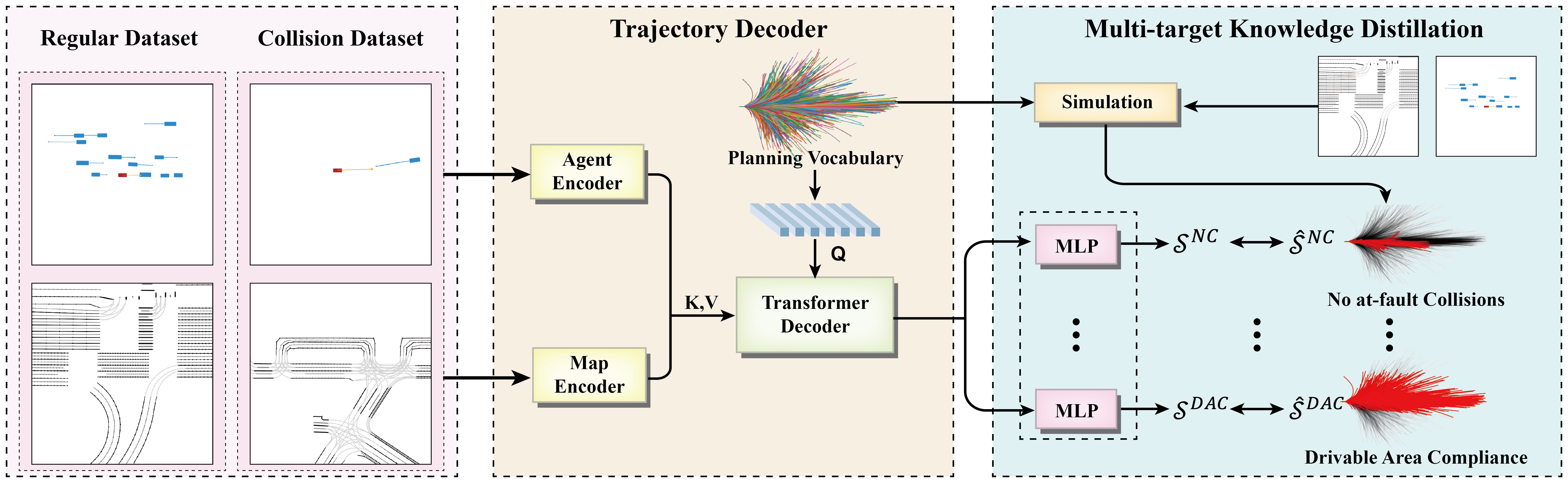
Zi Wang, Shiyi Lan, Xinglong Sun, Nadine Chang, Zhenxin Li, Zhiding Yu, Jose M. Alvarez
IROS 2025
Paper / Project Page
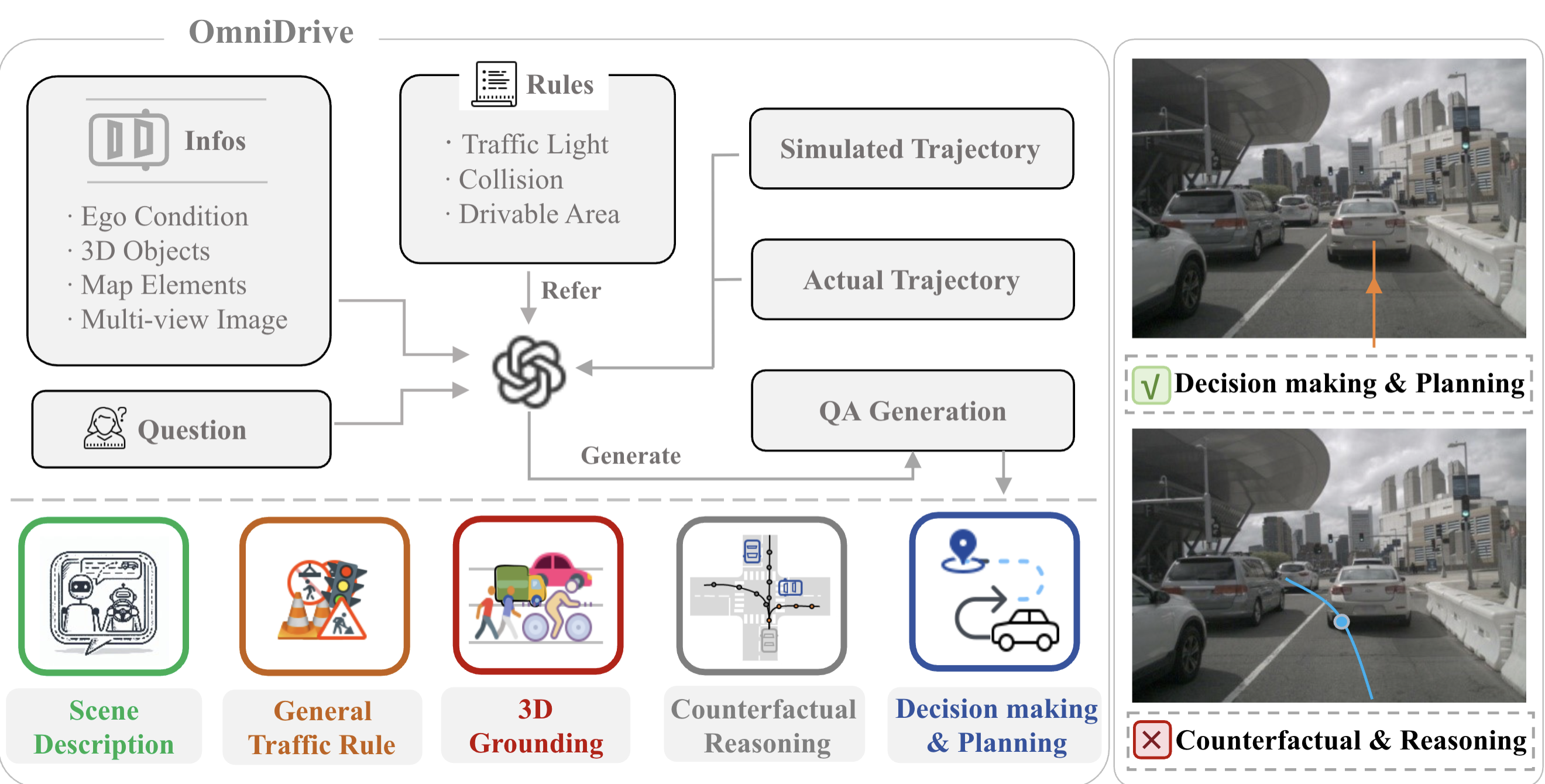
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, Jose M. Alvarez
CVPR 2025
Paper / Code