Towards Viewpoint Robustness in Bird's Eye View Segmentation
Abstract
Autonomous vehicles (AV) require that neural networks used for perception be robust to different viewpoints if they are to be deployed across many types of vehicles without the repeated cost of data collection and labeling for each. AV companies typically focus on collecting data from diverse scenarios and locations, but not camera rig configurations, due to cost. As a result, only a small number of rig variations exist across most fleets. In this paper, we study how AV perception models are affected by changes in camera viewpoint and propose a way to scale them across vehicle types without repeated data collection and labeling. Using bird's eye view (BEV) segmentation as a motivating task, we find through extensive experiments that existing perception models are surprisingly sensitive to changes in camera viewpoint. When trained with data from one camera rig, small changes to pitch, yaw, depth, or height of the camera at inference time lead to large drops in performance. We introduce a technique for novel view synthesis and use it to transform collected data to the viewpoint of target rigs, allowing us to train BEV segmentation models for diverse target rigs without any additional data collection or labeling cost. To analyze the impact of viewpoint changes, we leverage synthetic data to mitigate other gaps (content, ISP, etc). Our approach is then trained on real data and evaluated on synthetic data, enabling evaluation on diverse target rigs. We release all data for use in future work. Our method is able to recover an average of 14.7% of the IoU that is otherwise lost when deploying to new rigs.
Paper

Towards Viewpoint Robustness in Bird's Eye View Segmentation
Tzofi Klinghoffer, Jonah Philion, Wenzheng Chen, Or Litany, Zan Gojcic, Jungseock Joo, Ramesh Raskar, Sanja Fidler, Jose Alvarez
Technical Video
The Viewpoint Robustness Problem
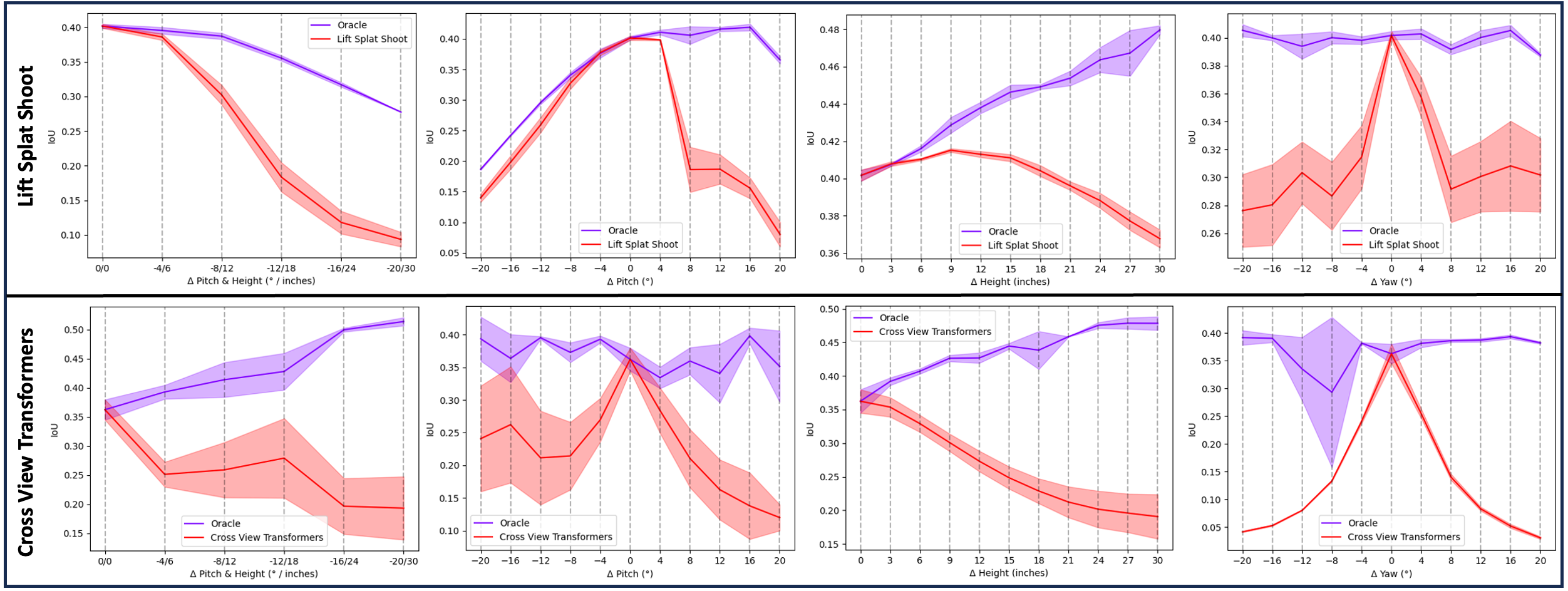
We train a source BEV model using Lift Splat Shoot and Cross View Transformers, denoted at point 0 on the x axis of each graph. We then test the model across different target rigs where the camera pitch, yaw, height, or pitch and height are changed, as denoted by the different points along the x axes. We also trained each model on the target rig directly and refer to this model as the ”oracle”, as it reflects the expected upper bound IoU for each viewpoint.
To quantify the impact of training a perception model on data from one camera viewpoint (the source rig) and testing on another camera viewpoint (the target rig), we run extensive experiments in simulation. We train on data from a source rig and then vary either the pitch, yaw, height, or pitch and height together. We find that even small changes in camera viewpoint lead to significant drops in perception model accuracy.
Method
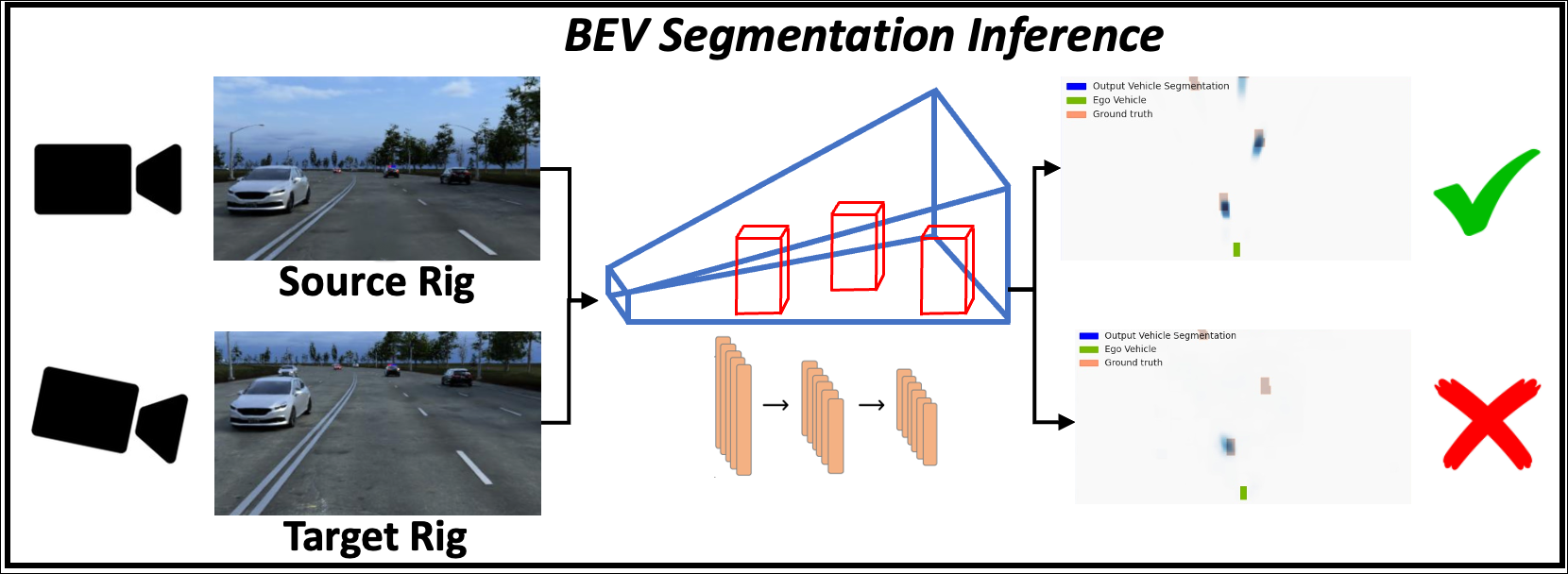
Current methods for bird’s eye view (BEV) segmentation are trained on data captured from one set of camera rigs (the source rig). At inference time, these models perform well on that camera rig, but, according to our analysis, even small changes in camera viewpoint lead to large drops in BEV segmentation accuracy. Our solution is to use novel view synthesis to augment the training dataset. We find this simple solution drastically improves the robustness of BEV segmentation models to data from a target camera rig, even when no real data from the target rig is available during training.
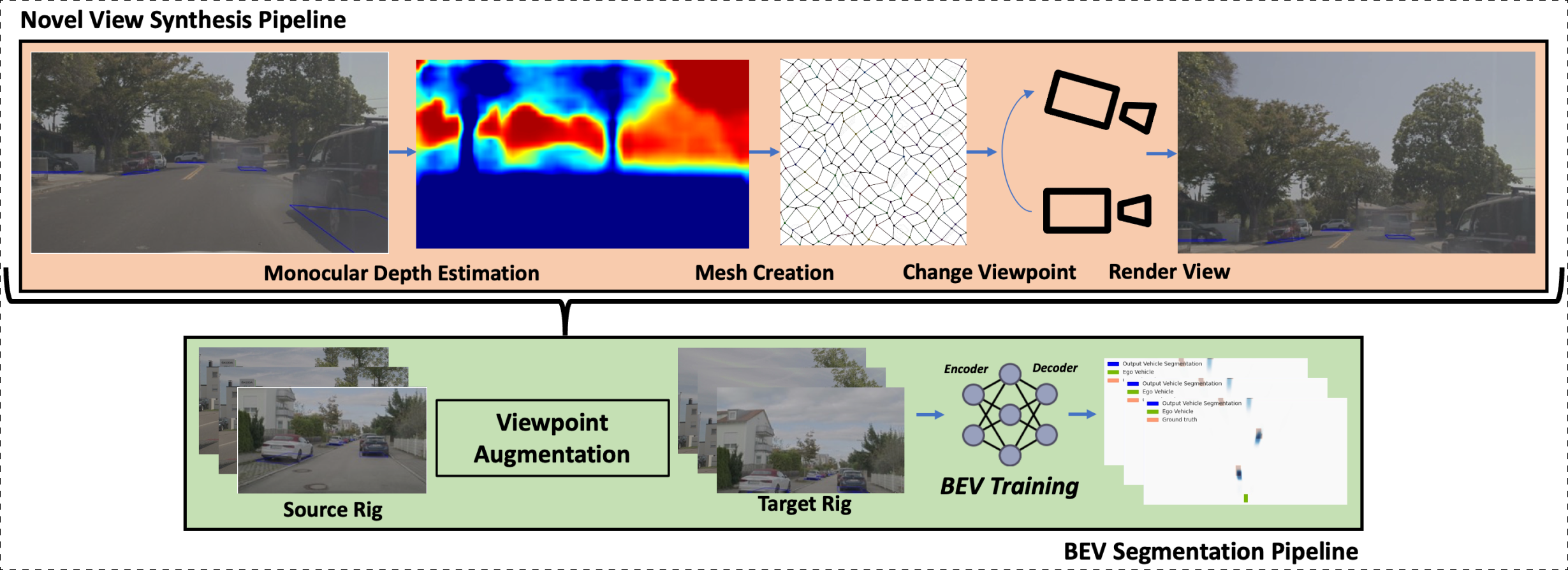
We propose a method for novel view synthesis for complex autonomous vehicle (AV) scenes. Our approach builds off of Worldsheet, a recent method for novel view synthesis, that uses monocular depth estimation to transform the scene into a textured mesh, which can be used to render novel views. We use LiDAR data to supervise depth estimation, automasking to improve the quality of the LiDAR depth maps, SSIM loss to improve training robustness, and apply only the minimal loss between neighboring frames to improve performance on scenes with occlusions. More ablations are included in the paper.
Results

Shown above are the novel view synthesis results (rectified) obtained with our method for novel view synthesis. We transform images from the source rig to each of the target viewpoints and then use them for BEV segmentation training.
We find that our method is able to produce realistic changes in camera viewpoint from monocular images. We then use these images to re-train the BEV segmentation model for the target viewpoint. As a result, BEV segmentation accuracy (IoU) significantly increases, removing the viewpoint domain gap. The improvement in performance achieved with our method is highlighted in the videos before. Without our method, we see that the BEV segmentation model is unable to generalize to a different viewpoint (middle), whereas, with our method, it is able to perform well on the target viewpoint (right).
(Left) Performance of model trained and tested on sedan viewpoint, (Middle) Performance of model trained on sedan and tested on SUV viewpoint, (Right) Performance of model trained on trained on sedan transformed to SUV with our approach and tested on SUV.
Citation
@inproceedings{tzofi2023view,
author = {Klinghoffer, Tzofi and Philion, Jonah and Chen, Wenzheng and Litany, Or and Gojcic, Zan
and Joo, Jungseock and Raskar, Ramesh and Fidler, Sanja and Alvarez, Jose M},
title = {Towards Viewpoint Robustness in Bird's Eye View Segmentation},
booktitle = {International Conference on Computer Vision},
year = {2023}
}
Acknowledgements
We thank Alperen Degirmenci for his valuable help with AV data preparation and Maying Shen for her valuable support with experiments.