An atlas of 7,361 scenes,
604K masks, 3M captions.
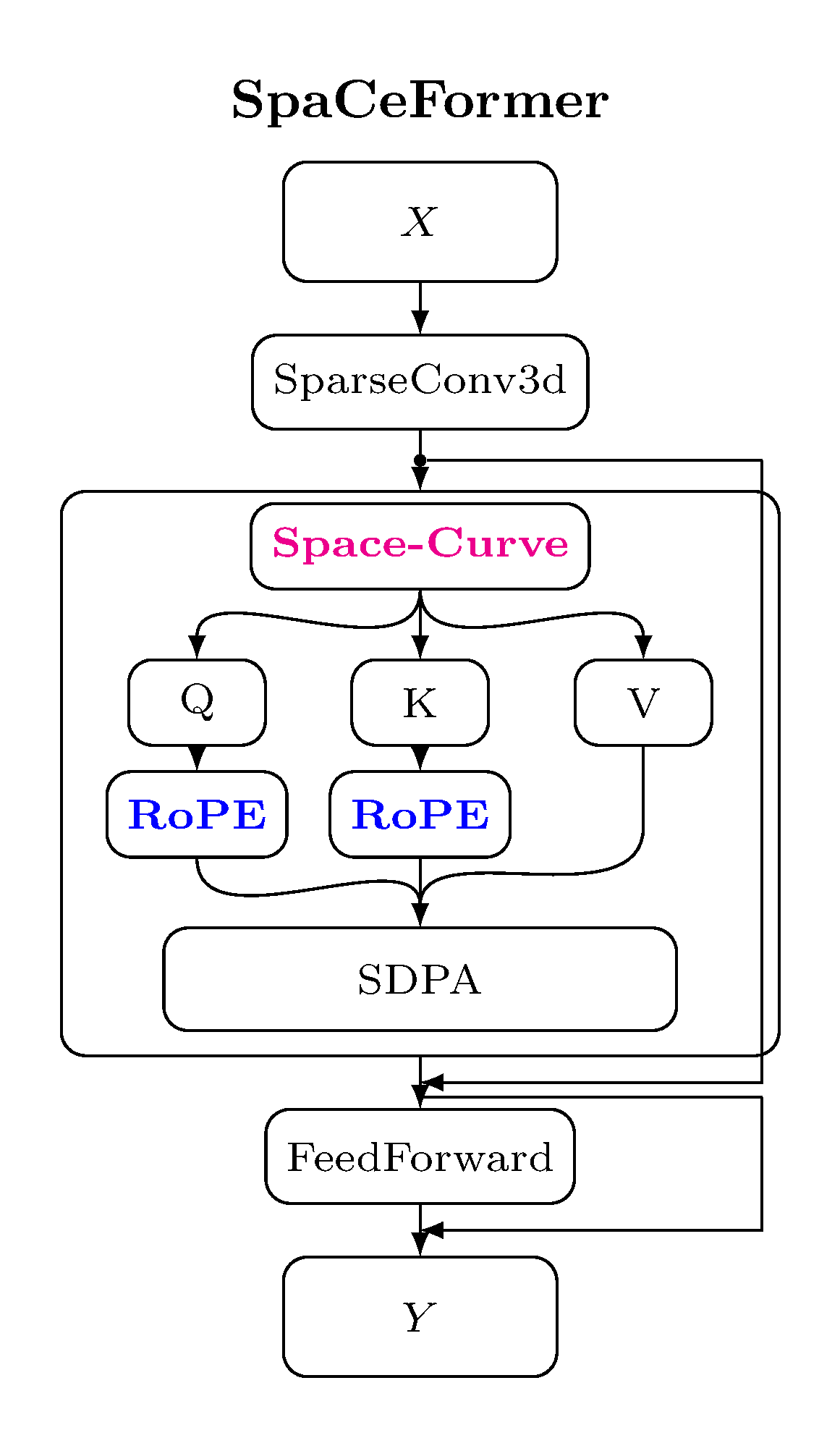
We construct SpaCeFormer-3M, the largest open-vocabulary 3D instance segmentation training corpus. Using training-free multi-view mask clustering and structured VLM prompting, we generate 604K instance masks with 3M diverse captions across 7,361 indoor scenes — without any human annotation.
| Source Dataset | Scenes | Instance Masks | Captions | Avg Masks / Scene |
|---|---|---|---|---|
| ScanNet | 1,201 | 79,320 | 396,600 | 66.0 |
| ScanNet++ | 223 | 27,296 | 136,480 | 122.4 |
| ARKitScenes | 4,497 | 446,409 | 2,232,045 | 99.3 |
| Matterport3D | 1,440 | 51,102 | 255,510 | 35.5 |
| Total | 7,361 | 604,127 | 3,020,635 | 82.1 |
Mask quality vs. ground truth · 312 ScanNet train scenes
Auto-generated training masks benchmarked against GT instance annotations at IoU > 0.5. Compared to Mosaic3D's SAM2-based 2D-to-3D lifting, SpaCeFormer-3M achieves 21× higher recall (54.3% vs. 2.5%) — multi-view aggregation produces substantially more complete, geometry-consistent instances.
| Source | Masks/Scene | Mean best-IoU | Precision @0.5 | Recall @0.5 | IoU > 0.50 |
|---|---|---|---|---|---|
| Mosaic3D (SAM2 lifting) | 16.1 | 0.247 | 4.8% | 2.5% | 3.8% |
| SpaCeFormer-3M (Ours) | 65.2 | 0.251 | 33.6% | 54.3% | 25.9% |
Plates · Instance galleries from the corpus
Each 3D instance mask is paired with 5 diverse captions generated from multiple viewpoints, capturing shape, material, texture, and spatial context.
Scene 0270 — Hotel Room

- The wooden entertainment center features a warm, honey-toned finish and provides storage and display space for electronics.
- A medium-sized, rectangular unit with a dark brown hue sits adjacent to a desk, offering a dedicated space for a television.
- This cabinet-like structure offers ample storage with its multiple drawers, suitable for organizing media components and accessories.
- Crafted from wood, the built-in unit's design integrates seamlessly into the room's decor, providing a sturdy base for a television.
- The brown wooden cabinet, with its integrated shelf, stands near a desk, offering a functional and aesthetically pleasing media storage solution.

- Dark metal rack with a tiered design, likely used for drying dishes or storing small items.
- The black, angular rack stands near a light-colored cabinet, its open structure creating visual contrast.
- A medium-sized, sturdy rack provides a surface for air-drying, positioned beside a wooden cabinet.
- Constructed from dark metal bars, the rack's design allows for ventilation and easy access to items.
- The angled rack, with its rectangular openings, sits adjacent to a cabinet, offering a practical storage solution.

- The wooden table features a warm, brown finish and a smooth, polished surface, ideal for supporting lamps and other decor.
- A medium-sized table with a scalloped edge sits adjacent to a cabinet, its shape complementing the room's traditional style.
- This small table offers a surface for placing items, providing a convenient spot for a phone or remote control.
- Crafted from wood, the table's design incorporates a single drawer and decorative cutouts, blending functionality with aesthetic appeal.
- Positioned near a chair, the brown wooden table provides a stable base for a lamp, creating a cozy reading nook.

- The bedframe is constructed from wood, providing structural support for the mattress and bedding.
- A dark brown bed frame with a rectangular headboard sits against a wall, adjacent to a bedside table.
- This medium-sized bed frame offers a comfortable place to rest, featuring a flat surface for pillows.
- The wooden headboard's design complements the hotel room's decor, creating a cohesive aesthetic.
- The bed frame's upper edge supports a white pillow, positioned near a lamp and artwork.
Scene 0601 — Living Room

- The red metal whiteboard serves as a surface for writing and displaying information, positioned against a dark red wall.
- A rectangular whiteboard with a red frame stands upright, offering a large, blank space for notes and diagrams.
- Medium-sized whiteboard, suitable for brainstorming or presentations, provides a writable surface near laundry machines.
- The whiteboard's flat surface and sturdy frame allow for easy cleaning and repeated use in a communal space.
- Red-painted metal whiteboard, mounted on the wall, offers a functional space for communication and collaboration.

- The small side table features a smooth, wooden tabletop and a dark gray metal stem, providing a surface for drinks or books.
- A round table with a warm brown wood top sits adjacent to a patterned armchair, creating a cozy seating area.
- This medium-sized table offers a convenient surface for placing items, easily accessible for resting a cup or phone.
- The table's simple, cylindrical design complements the surrounding furniture, blending seamlessly into the waiting room decor.
- Positioned next to a chair, the table's wooden surface and dark metal leg provide a functional and stylish accent.

- Upholstered chair with a textured, patterned fabric in shades of red, orange, and brown offers a comfortable seating option.
- The chair's rounded shape and reddish-brown hue complement the surrounding decor, positioned near a small table.
- A medium-sized chair provides a place to sit and rest, its sturdy frame suggesting durability and frequent use.
- The chair's design features a cutout back and a patterned upholstery, blending seamlessly into the waiting area's aesthetic.
- Located near a side table, the chair's fabric texture and reddish-brown color create a welcoming and functional seating arrangement.

- The large, white washing machine features a stainless steel drum and digital control panel, designed for laundry tasks.
- A white appliance with a rounded door sits adjacent to other machines, displaying a modern, streamlined shape.
- This medium-sized washing machine offers a convenient space for loading clothes, facilitating household chores.
- The appliance's durable white plastic exterior integrates seamlessly into the laundry room's utilitarian design.
- Positioned between other washers, the white machine's front-loading door and digital display indicate its operational status.
Scene 0656 — Bedroom

- A small, dark wood nightstand provides storage near the bed, featuring brass-toned hardware and a traditional design.
- The reddish-brown bedside table sits adjacent to the bed, its rectangular shape complementing the room's layout.
- This medium-sized wooden cabinet offers a surface for lamps and books, easily accessible from the bed.
- Crafted from wood with a visible grain, the nightstand's design blends classic style with functional storage.
- The dark brown nightstand, positioned next to the bed, provides a convenient spot for personal items and a lamp.

- The pillow's woven fabric offers a soft, comfortable surface for resting.
- A rectangular pillow with a muted brown and black checkered pattern rests against the bed.
- Medium-sized pillow, suitable for supporting the head during sleep or relaxation.
- The pillow's design complements the bedroom's decor, providing a cozy accent.
- Positioned against the headboard, the pillow offers support and adds visual texture to the bed.

- Dark brown wooden table with ornate carved details, providing a surface for small items.
- Rectangular table with a glossy finish, positioned near a curtain and a chair.
- Medium-sized table offering a flat surface for holding stationery and decorative objects.
- The table's design features cabriole legs and a drawer, blending into the room's decor.
- A dark wood table sits adjacent to a chair, providing a functional space for writing or display.

- The chair's dark fabric upholstery provides a comfortable seating surface, designed for supporting a person.
- A medium-sized chair with a curved backrest sits adjacent to a dark wooden desk, displaying a classic design.
- This chair offers a place to sit; its slender frame allows for easy movement around the room.
- The chair's metal legs and dark fabric seat create a simple, functional design, blending into the room's decor.
- Positioned near a desk, the chair's dark color contrasts with the lighter carpet, offering a spot for focused work.