Abstract
We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
Links

Overview
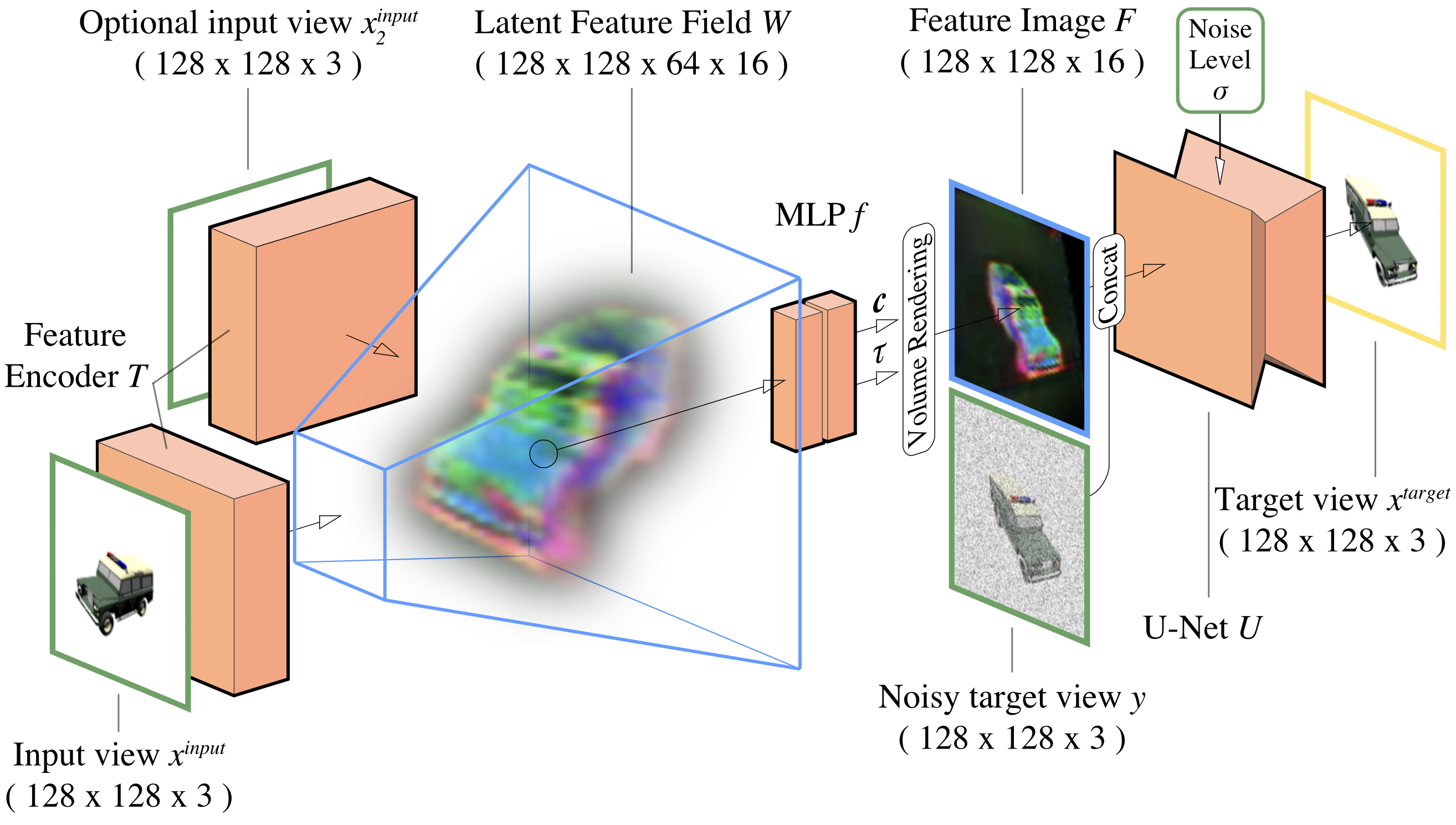
At a high level, our model operates as a conditional diffusion model for images, much like the models that have been successful in image inpainting, superresolution, and other conditional image generation tasks. Conditioned on an input view, we generate novel views by progressively denoising a sample of Gaussian noise. However, in this work, we embed 3D priors into the architecture in the form of a 3D feature field, which enhances the model's ability to synthesize views on complex scenes.
We lift and aggregate features from input image(s) into a 3D feature field. Given a query viewpoint, we volume-render a feature image to condition a U-Net image denoiser. The entire model, including feature encoder, volume renderer, and U-Net components, is trained end-to-end as an image-conditional diffusion model. At inference, we generate consistent sequences in an auto-regressive fashion.
Videos
The following videos demonstrate novel view synthesis with our method, which produces high-quality, multi-view-consistent renderings on varied datasets.
Citation
@inproceedings{chan2023genvs,
author = {Eric R. Chan and Koki Nagano and Matthew A. Chan and Alexander W. Bergman and Jeong Joon Park and Axel Levy and Miika Aittala and Shalini De Mello and Tero Karras and Gordon Wetzstein},
title = {{GeNVS}: Generative Novel View Synthesis with {3D}-Aware Diffusion Models},
booktitle = {arXiv},
year = {2023}
}License
Images, text and video files on this site are made freely available for non-commercial use under the Creative Commons CC BY-NC 4.0 license . Feel free to use any of the material in your own work, as long as you give us appropriate credit by mentioning the title and author list of our paper.
Acknowledgments
We thank David Luebke, Samuli Laine, Tsung-Yi Lin, and Jaakko Lehtinen for feedback on drafts and early discussions. We thank Jonáš Kulhánek and Xuanchi Ren for thoughtful communications and for providing results and data for comparisons. We thank Trevor Chan for help with figures. Koki Nagano and Eric Chan were partially supported by DARPA’s Semantic Forensics (SemaFor) contract (HR0011-20-3-0005). JJ park was supported by ARL grant W911NF-21-2-0104. This project was in part supported by Samsung, the Stanford Institute for Human-Centered AI (HAI), and a PECASE from the ARO. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Government. Distribution Statement ``A'' (Approved for Public Release, Distribution Unlimited). We base this website off of the StyleGAN3 website template.