3 Path Solver

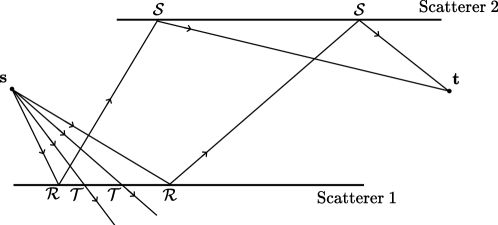
A path solver aims to determine a set of paths that connect two endpoints in a scene, as illustrated in Figure 7. From this set of paths, a time- or frequency-domain CIR can be computed. The path solver leverages SBR to efficiently compute paths in a scene. SBR operates as follows: First, rays22 2 The processing of the rays is parallelized for accelerated computation. are traced from the source into directions specified by a lattice on the unit sphere (see Section 3.1.1). Then, an SBR loop iteratively tests the intersection of the rays with the scene geometry. At every intersection, an interaction type is selected from , and a new ray is spawned according to the selected interaction type. The method for choosing interaction types is detailed in Section 3.1.2. The loop terminates when no more rays remain active, meaning they have either bounced out of the scene, reached a predefined maximum number of bounces, or satisfied another termination criterion. Notably, at each interaction of a ray with a surface in the scene, only one scattered ray is spawned, as spawning multiple rays would result in an exponential increase in the number of rays, quickly overwhelming the available computational resources.
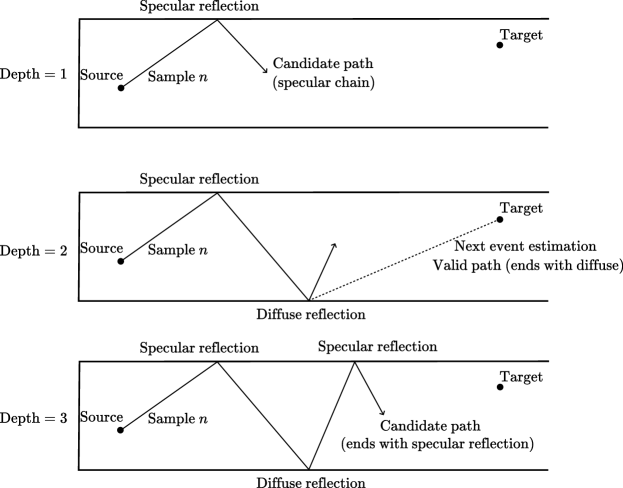
When a diffuse reflection occurs during the SBR loop, the solver checks whether there is a line-of-sight (LoS) to the target, meaning that the ray segment from the interaction point to the target point is not occluded. If such a connection exists, the path is deemed valid and is returned by the solver. This process is known as next-event estimation. Subsequently, a new ray is spawned in a random direction within the hemisphere defined by the surface normal of the primitive involved. This new ray may lead to the discovery of additional paths. Next-event estimation is only possible for diffuse reflections that scatter energy into all directions. For specular reflection and refraction, only a single ray is spawned in the only possible direction. Consequently, the probability of finding paths connecting the source to the target that end with a specular reflection or refraction by SBR is effectively zero, as depicted in Figure 8(a). This is because hitting a specific point (the target) with a specular reflection or refraction requires perfect alignment of the incident ray, which has zero probability in continuous space. Likewise, for diffraction, the probability that the target is on the surface of the Keller cone is zero, as shown in Figure 8(b). When diffraction occurs, a single ray is spawned in a random direction along the Keller cone to continue the sample. Paths ending with a specular suffix can therefore not be determined solely by SBR. In particular, specular chains cannot be computed by SBR. Since specular chains typically carry a significant amount of the transported energy, SBR alone is insufficient for computing CIRs.

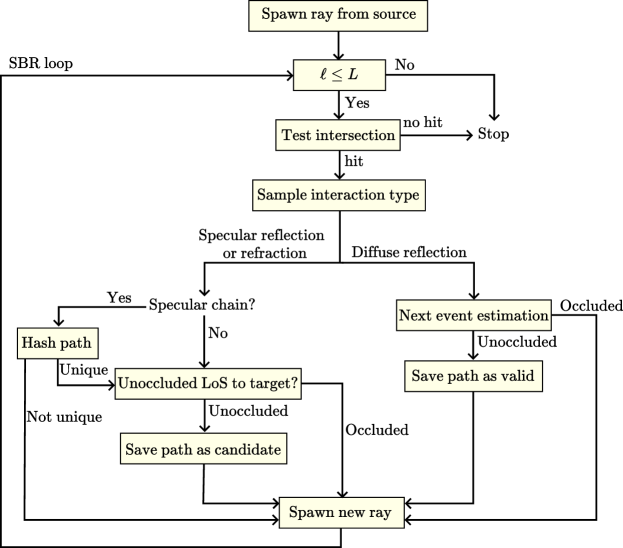
To compute paths ending with a specular suffix, including specular chains, the path solver uses an image method-based algorithm. However, a brute-force implementation of the image method that would test all possible combinations of primitives and wedges that constitute the scene is prohibitive even for moderately large scenes. Therefore, the path solver uses SBR as a heuristic to find path candidates. A path candidate consists of a sequence of primitives or wedges and interaction types ending with a specular reflection, refraction, or diffraction. As the path vertices determined during the SBR do not form a path that connects to the target, the image method is used to adjust the vertex locations to establish the connection. Intuitively, SBR pre-selects path candidates in the vicinity of the transmitter and receiver for the image method to compute corresponding valid paths to be returned by the solver. These steps of the Sionna RT path solver are depicted in Figure 9. Notably, only path candidates ending with a specular suffix (including specular chains) require further processing by the image method algorithm. Finally, for each valid path identified, the path solver computes the corresponding channel coefficients and propagation delays that characterize the EM wave propagation along that path.
Alternative methods for identifying paths that include specular chains or specular suffixes may involve detection spheres centered at the targets to capture paths ending with a specular suffix, and/or extending the direction of specular reflection (or refraction) to a lobe around the specular, refracted, or diffracted direction. Such methods only approximate the path vertex locations and the directions of the scattered rays, yielding inaccurate path coefficients and resulting in incorrect CIRs.
The remainder of this section follows the architecture of the path solver shown in Figure 9. First, Section 3.1 presents the SBR-based candidate generator. Section 3.2 then describes the image method-based algorithm that processes candidates to find valid paths with specular suffixes. Section 3.3 details how the solver computes the complex-valued channel coefficients and propagation delays, which characterize the radio channel. Finally, Section 3.4 discusses current limitations and potential improvements of the path solver.
3.1 Generating Candidates by Shooting and Bouncing of Rays (SBR)
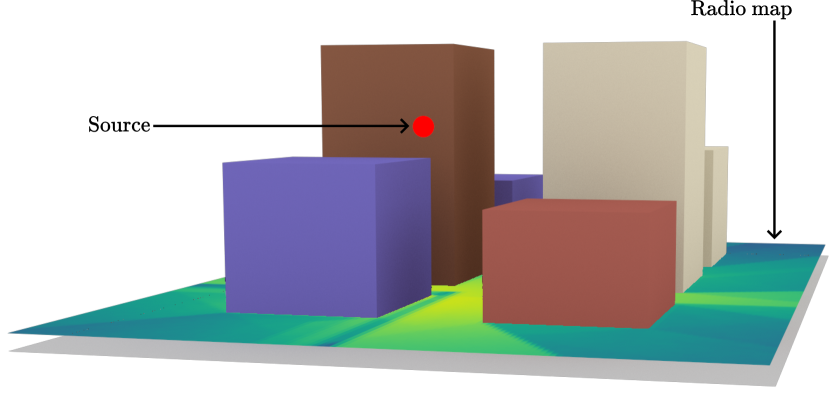
The candidate generator utilizes the SBR-based method as illustrated in Figure 10. We first provide an overview of the SBR procedure, followed by a detailed explanation. We consider a scene with a single source located at and targets at , where . Although the path solver built into Sionna RT can handle multiple sources, we focus on a single source for the sake of clarity. The process is identical for all sources. The paths traced by the candidate generator during the SBR procedure are referred to as samples in this section to avoid confusion with the valid paths returned to the user and the candidate paths forwarded to the image method-based algorithm. A sample therefore consists of a sequence of rays connected end-to-end, traced by the candidate generator. As we will see, a single sample can result in multiple valid or candidate paths, as illustrated in Figure 11.
The SBR procedure begins by spawning a user-specified number of rays, denoted by , from the source in directions on a Fibonacci lattice, where . Each ray starts a sample that is traced by the candidate generator. Details on the implemented Fibonacci lattice can be found in Section 3.1.1. The SBR loop then iterates until either all samples bounce out of the scene or reach a user-specified maximum number of bounces, denoted as the maximum depth . We denote the depth of the samples by . The first step of the SBR loop involves testing the intersection of the samples with the scene geometry. If a sample does not intersect any object, it has bounced out of the scene, and is deactivated. When a sample with depth intersects the scene, we denote by the intersection point, by the surface normal at the intersection point oriented towards the half-space containing the incident field, by the index of the intersected object, and by the index of the specific intersected primitive within that object. The interaction type, denoted by , is then sampled from , determining how the sample will continue to propagate. Details on the sampling of the interaction type are provided in Section 3.1.2. The rest of the loop depends on the sampled interaction type.
Diffuse Reflection
As previously indicated, diffuse reflection is assumed to scatter energy in all directions of the half-space containing the incident field, which enables next event estimation. Therefore, if a diffuse reflection is sampled (i.e. ), the LoS between the intersection point and each target is tested. For each target with an unobstructed LoS to the intersection point, a path connecting the source to the target
| (11) |
is recorded as a valid path to be returned to the user. Finally, a new ray is spawned to continue the sample path, with its direction selected uniformly at random from the hemisphere defined by , i.e. , where represents the uniform distribution on the hemisphere.
Specular Reflection and Refraction
When a specular reflection or refraction is sampled (i.e. or ), the path (11) is a valid path for target , where , only if
| (12) |
where
| (13) |
and where denotes the transpose of . Since targets are modeled as points, condition (12) effectively occurs with zero probability, and, consequently, the path (11) is not a valid path. However, the specular suffix , where is defined as in (10), can be further processed to determine vertices such that
| (14) |
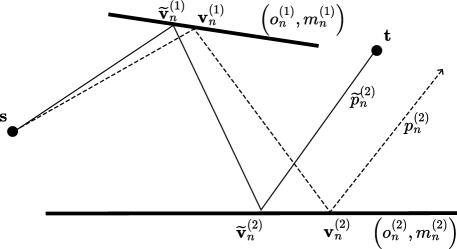
is a valid path, as illustrated in Figure 12. This additional processing is performed using the image method in the algorithm described in Section 3.2.
Importantly, for a sequence of primitives and interaction types
| (15) |
where , there exists at most a single set of vertices such that is a valid path. Consequently, if , i.e. is a specular chain, then further processing by the image method of multiple identical candidates (15) would result in multiple identical valid paths, which would lead to erroneous CIRs. Therefore, if the sample is a specular chain, a hashing-based de-duplication mechanism, detailed in Section 3.1.3, ensures that specular chain candidates are only evaluated once. Notably, the path hashing mechanism discards redundant candidates “on-the-fly”, significantly reducing memory and compute requirements. However, when , then corresponds to a diffuse reflection point that is the result of a randomly sampled ray direction (either at the source or the last previous diffuse reflection point). Since the probability of two different paths having identical randomly sampled diffuse reflection points is effectively zero, path uniqueness is guaranteed in these cases without requiring the de-duplication mechanism.
Diffraction
When tracing rays, the probability that a ray exactly intersects the edge of a wedge is zero. Therefore, when a ray intersects a primitive and diffraction is sampled (i.e., ), the intersection point between the ray and the primitive is projected onto one of the primitive’s edges, yielding the vertex , as illustrated in Figure 13. The index of the edge onto which the intersection point is projected is denoted by .
The path (11) is a valid path to a target (with ) only if there exists an angle , where is the exterior angle of the wedge, such that
| (16) |
with the diffraction direction given by
| (17) |
where is the angle between the incident ray direction and the wedge vector , and is an orthonormal basis such that (see Figure 13). Note that is tangent to the wedge face. In (17), ensuring that the angle between the diffracted ray and the edge, denoted by , matches the angle between the incident ray and the edge, places the ray on the Keller cone. As with specular reflection and refraction, since targets are modeled as points, condition (16) is satisfied with zero probability for all , rendering the sampled path invalid. Therefore, candidate paths ending with a diffraction are further refined using the image method-based algorithm described in Section 3.2, just as for paths ending with specular reflection or refraction. As shown in Figure 10, the processing of diffraction thus follows the same steps as for specular reflection and refraction: a hashing-based de-duplication mechanism ensures uniqueness of specular chains, and an occlusion test to the target is used as a heuristic to eliminate candidates unlikely to produce valid paths after refinement with the image method. Finally, a new ray is traced in the direction (17) to continue the sample path, with sampled uniformly from .
As illustrated in Figure 13, projecting the intersection point onto an edge alters the scattered ray direction departing from . This modification invalidates any preceding specular reflections or refractions, meaning that path segments that are not suffixes would require refinement if a diffraction is followed by a diffuse reflection. To avoid significantly increased computational complexity from refining non-suffix path segments, the path solver prohibits sampling paths that contain both diffraction and diffuse reflection. Such paths typically contribute negligibly to the total transported energy and therefore have little impact on the accuracy of the CIRs. Moreover, Sionna RT currently supports only first-order diffraction, meaning that paths may contain at most one diffraction event.
The candidate generator depicted in Figure 10 thus yields a set of valid paths connecting the source to all targets that do not require further processing (except for the computation of the corresponding path coefficients and delays) and end with a diffuse reflection. Additionally, it produces a set of candidate paths ending with specular suffixes, which require further processing to be either discarded or refined into valid paths.
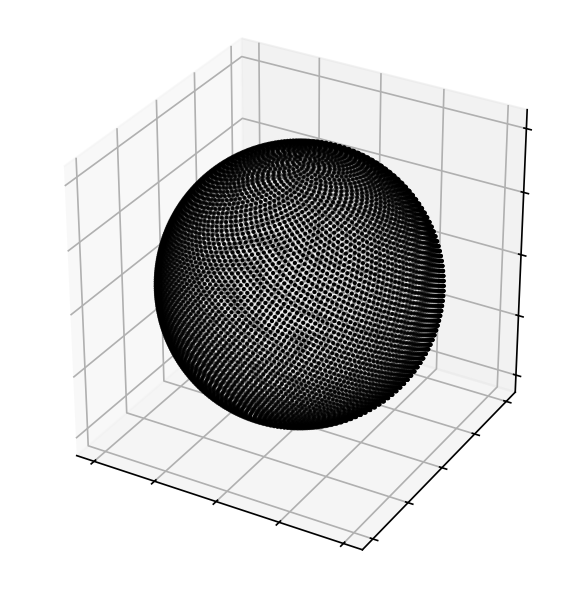
3.1.1 Sampling Initial Ray Directions
The SBR procedure starts by spawning rays from the source with directions obtained from a spherical Fibonacci lattice with points, which is defined as follows:
| (18) |
where
and , is the golden ratio, and and the floor and ceiling function, respectively. Note that when defining the Fibonacci lattice, the index takes values in the range instead of the usual . Sampling rays from the Fibonacci lattice results in ray tubes sharing approximately the same opening angle .
The Fibonacci lattice was selected for its simple construction and its benefits over other lattices for numerical integration [13, 14]. Figure 14 shows the spherical Fibonacci lattice with 100, 1000, and 10000 points. The Sionna RT path solver uses points as the default value for , and higher values will ensure that more valid paths are found.
3.1.2 Sampling Interaction Types
Within the SBR loop, when a ray intersects the scene geometry, the algorithm generates at most one scattered ray. This constraint is necessary because generating multiple rays at each intersection, such as both reflected and refracted rays, would lead to an exponential increase in computational complexity and memory usage with the depth of the path. Instead, a single interaction type is randomly chosen based on a distribution:
| (19) |
Here, represents the probability of selecting the interaction type . Importantly, the choice of distribution does not affect the calculation of the paths’ electric fields, which are solely dependent on the propagation environment. However, the choice of distribution significantly impacts the sample efficiency of the ray tracer, which affects the number of samples needed to compute paths that connect a source to a target and capture the majority of the transported energy. Sampling only one interaction type per intersection may appear limiting, but this is offset by the large number of samples generated from each source. In most scenarios, a high sample count allows identifying all significant paths.
For each sample at depth , the interaction type is sampled independently for every interaction along every path. For specular reflection, diffuse reflection, and refraction, the probability of selecting each interaction type is proportional to the squared amplitudes of the corresponding reflection and refraction coefficients. Diffraction, on the other hand, is sampled using a fixed probability . This choice is motivated by the fact that diffraction typically carries much less energy compared to reflection and refraction, which would result in very low probabilities for sampling diffraction if its probability were also based on the diffraction coefficients. The resulting distribution for the interaction types is:
| (20) | ||||
In Sionna RT, is set to . Here, , , , and are the Fresnel coefficients (131), is the scattering coefficient (see Section A.9), and is the reflection reduction factor (164). This approach ensures that interaction types responsible for scattering more energy are sampled more frequently—-a technique known as importance sampling [15, 16]. This is similar to importance sampling techniques for light transport paths commonly used in computer graphics. A brief overview of importance sampling in the context of ray tracing for the simulation of radio wave propagation is provided in Appendix B.

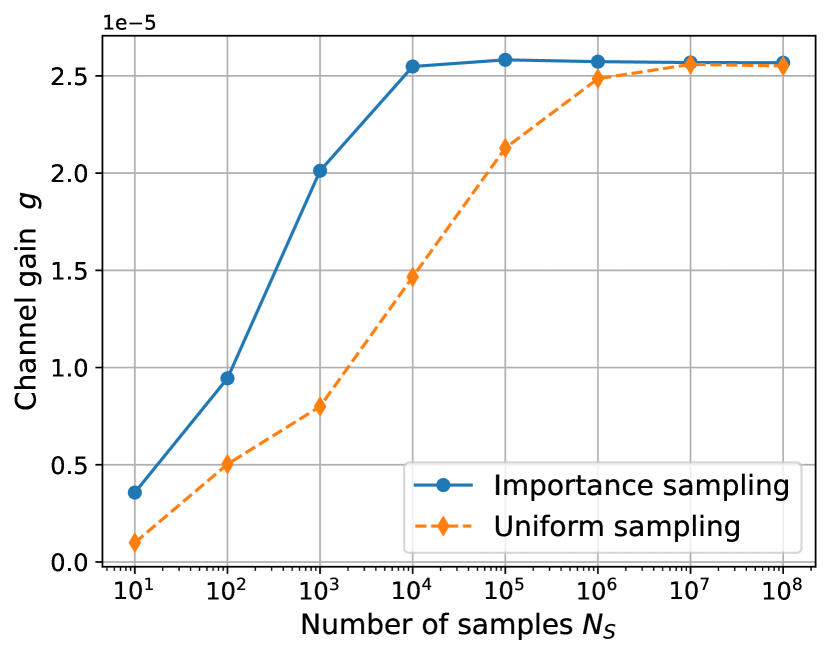
To illustrate the importance of optimized sampling strategies, we compare uniform sampling, where specular reflection, diffuse reflection, and refraction are selected with equal probability, to importance sampling using the scene shown in Figure 15(a). The scene consists of a metallic box containing a glass screen, with a source and target positioned on opposite sides. Diffuse reflection, specular reflection, refraction, and diffraction are enabled, and the maximum depth is set to . As shown in Figure 15(b), using importance sampling leads to better sample efficiency when compared to uniform sampling, as convergence requires approximately fewer samples to capture most of the received energy. This demonstrates the benefit of selecting interactions according to the material properties of the scatterers.
3.1.3 Specular Chain Candidates Deduplication
As mentioned in Section 3.1 and Figure 10, to avoid storing multiple identical specular chain candidates, a path hashing method is used to discard duplicates of previously found candidates “on-the-fly”. A specular chain candidate is defined by a sequence of interactions with the scene, each characterized by the intersected object , the corresponding intersected primitive , the diffracted edge (if ), and the interaction type with , i.e.
| (21) |
For specular chain candidates, we do not need to store the path vertices. If the candidate leads to a valid path, these vertices will be computed. Invalid candidates are discarded.
The hashing process guarantees that each specular chain candidate uniquely represents the geometry of a path after refinement with the image method (see Section 3.2). This is achieved by computing a hash value that uniquely identify the sequence of primitives constituting the path. Importantly, primitives that are coplanar (i.e., lie in the same plane) are treated as equivalent during hashing. This is because the image method assumes all reflection surfaces extend infinitely, making the exact in-plane position of a primitive irrelevant to the path geometry. Furthermore, refraction can be omitted from the hashing procedure since it does not change the ray direction and therefore does not alter the geometry of the path, as refraction is modeled without angular deflection. Figure 16 illustrates this concept: two candidate paths, and , yield to the same refined path , and thus they should share the same hash value. This holds even though only one candidate is refracted by primitive , and both are reflected by different but coplanar primitives and , respectively.
Algorithm 1 depicts how path hashing works during ray tracing to avoid computing duplicate specular chain candidates. It starts by initializing a hash value to for each sample being traced. Then, as the sample interacts with objects in the scene, the algorithm computes a hash value for each intersection, and updates the path hash by combining it with the hash of the intersection, creating a unique identifier for the entire sample up to that point. The computation of the interaction hash depend on the interaction type. For specular reflection, hashing is performed based on the primitive normal vector and an offset positioning the plane with respect to the origin. An integer hash value is then computed by sequentially combining the normal components and the offset using the FNV-1a hash function [17]. As numerical imprecision can lead to slight variations in the normal vectors of coplanar primitives, the real-valued normal components are quantized to a fixed precision and then converted to integers using a function prior to hashing. Discussion on the choice of the quantization function is provided below. For diffraction, hashing is performed on the two edge endpoints by applying the FNV-1a hash function sequentially to the components of the endpoints. In both ) and ), the first call to the FNV-1a hash function uses a large constant H to seed the hash function.
Once the interaction hash is computed, the hash_update function updates the sample hash value through a polynomial rolling hash function [18] with a prime base of . For each new intersection, it updates the running hash by multiplying the current hash value by the prime number and adding the new intersection hash. When a specular chain candidate is considered for a target , the hash value of the candidate is paired with the target index to form a new hash value
| (22) |
This ensures that the specular chain candidate is unique for each target.
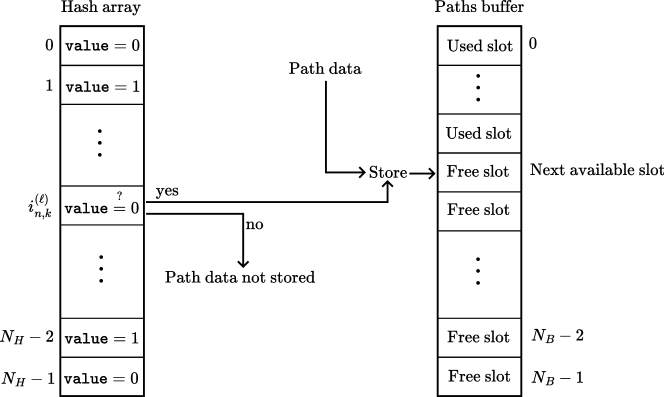
Practical Consideration: Hash Array
To track information about previously encountered specular chains, an array of integers of size is allocated in memory and initialized to zero, referred to as the hash array. When considering a specular chain candidate for target with corresponding hash value , the corresponding index in the hash array is computed as
| (23) |
If the hash array entry at index is greater than zero, it indicates that this path has already been encountered and should be discarded. Otherwise, the entry is incremented by one and the candidate is retained for further processing by the image method. It is important to note that the index is not guaranteed to be unique for different specular chains. When two different specular chains share the same index value despite being different, the path solver will discard one of them. Such an event is referred to as a collision, and can result in the discarding of valid paths. However, when two candidates are identical, their indices values will also be identical.
Valid paths and candidates are stored in a buffer of size . This buffer holds, for each path, the sequence of interaction types, vertices, intersected objects, primitives, and more. When a valid path is found or a candidate is identified as unique, indicated by its corresponding entry (23) in the hash array being set to zero, the path data are stored in the buffer. It is important to note that the index is solely used for indexing the hash array and not for storing path data in the buffer. Instead, path data are stored contiguously in the next available slot of the path buffer, as shown in Figure 17. If the buffer becomes full, any newly found paths or candidates are discarded. Discarding paths rather than overwriting existing ones is based on the reason that paths with lower depth, which are added to the buffer first as the SBR loop advances from to , typically carry more energy and should not be replaced by higher depth paths when the buffer becomes full. Consequently, the buffer size determines the maximum number of paths and candidates that can be stored.
Due to the substantial amount of data stored for each path, setting to excessively high values can lead to memory issues. This necessitates separating the hash array size from the buffer size . This is because a small hash array size can increase the probability of collisions. To reduce the risk of collisions, is set to
| (24) |
ensuring a minimum array size of elements. In the interface of the Sionna RT built-in path solver, corresponds to the samples_per_src parameter, and corresponds to max_num_paths_per_src.
Practical Consideration: Quantization Function
An important practical consideration is the design of the quantization function . When quantizing floating-point values to integers, values that are very close but lie on opposite sides of a quantization boundary can be mapped to different integers and therefore yield different hash values. For example, with rounding as the quantization function, and . This can cause identical candidates, which differ only due to numerical imprecision, to be treated as distinct, resulting in duplicate paths. To mitigate this issue, multiple hash values are computed for each sample, each using a different quantization function. A path is only considered unique if all of its corresponding hash values are unique. In the current implementation of Sionna RT, two quantization functions are used: rounding and floor, leading to two hash values being computed per candidate. This approach can be interpreted as a form of locality-sensitive hashing [19], as it aims to group together candidates that differ only due to numerical imprecision by using multiple hash functions to reduce the risk of misclassification.
3.2 Image Method-based Candidate Processing
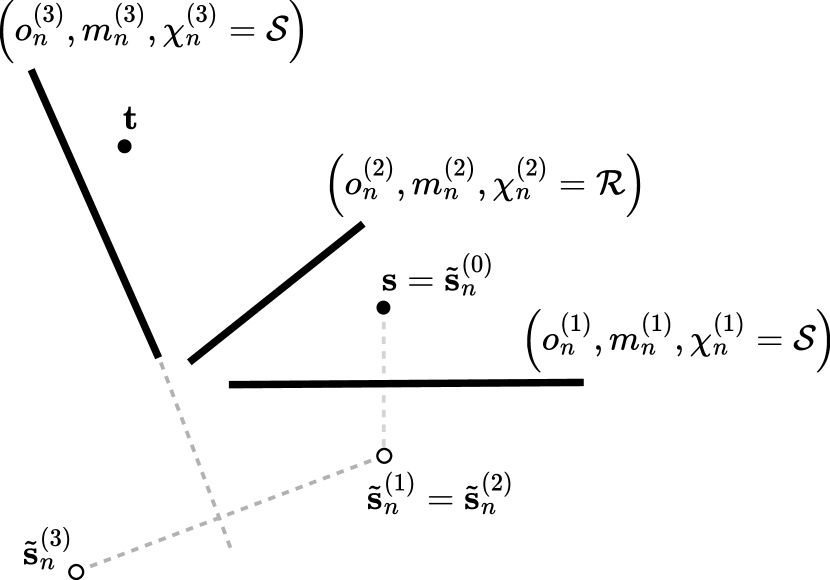
The image method processes path candidates to determine valid paths that are specular chains, or end with specular suffixes. Consider a candidate path
| (25) |
where denotes the path depth, is the specular suffix index defined as in (10), and is the target of the path. Recall that the sequence of interactions was determined by the SBR-based candidate generator. For path candidates that end with a specular suffix but are not specular chains (i.e. ), the image method processes only the specular suffix. In these cases, the vertex of the last diffuse reflection serves as the source point for the image method calculations. Since the processing algorithm is identical for both specular chains and specular suffixes, we treat them equivalently in the following discussion. For simplicity of notation, we will refer to both types as specular chains and assume throughout the remainder of this section.
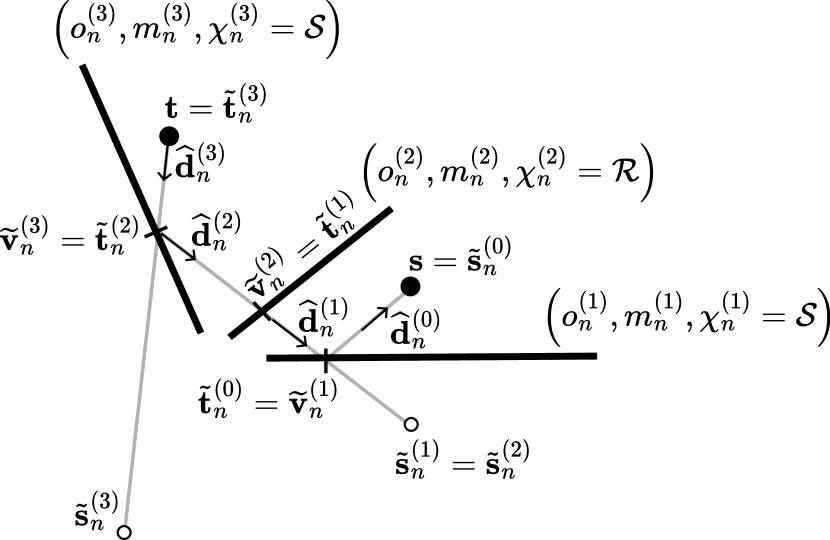
Paths without Diffraction
We begin by describing the image method process for candidates that contain no diffraction; as illustrated in Figure 18, this process consists of two main steps. First, the method iteratively computes images of the source by reflecting it across each plane at which a specular reflection occurs. Since refracted paths are modeled without angular deflection, incorporating refraction into the image method is straightforward: refractions may simply be skipped when computing the source images, as they do not alter the ray’s direction. Then, the algorithm backtracks from the target to determine the actual path vertices by intersecting lines between successive image sources.
Formally, the image method iteratively computes images of the source for , starting from the original source :
| (26) |
Here, represents any point on the plane containing the primitive , and denotes the surface’s normal vector. For specular reflections (), the image is computed by reflecting the previous image across the surface plane, while for refractions (), the image position remains unchanged.
During backtracking, the algorithm traces rays iteratively from the target back to the source by intersecting lines between successive image points. The intersection points are the refined vertices of the path. Specifically, a sequence of rays , , is traced, where and
| (27) | ||||
where is the intersection point between the ray and the primitive , as shown in Figure 18(b). The path is considered valid only if two conditions are met: (i) each ray successfully intersects a primitive that is coplanar with the primitive , and (ii) the line segment between and is unobstructed by any other scene geometry. If either condition fails, then the path is discarded. The case corresponds to the final segment of the path, which connects to the source . If the path is valid, then the returned path will be (14).
Paths with Diffraction
To handle paths involving diffraction, we adopt an approach inspired by [20]. Since Sionna RT currently only supports first-order diffraction, each sample contains at most a single diffracting edge, whose position within the path is denoted by . For notational simplicity, we omit the explicit dependence of on .
The core idea is to use image theory to compute the diffraction point in image space and subsequently map it back to the original space. The motivation for this approach is that, in the image space, all specular reflections and refractions are effectively “removed”, leaving only the diffraction event. This reduces the problem to a simpler form: finding the appropriate diffraction point for a path of the shape source diffraction target. More precisely, for every sample , the diffracting edge at depth , which is characterized by an endpoint and an edge vector , has its images computed by reflecting its endpoint and edge vector across each plane at which a specular reflection occurs over the following interactions :
| (28) | ||||
where represents any point on the plane containing the primitive , and denotes the surface’s normal vector. Applying image theory, specular reflections and refractions can be ignored when searching for the diffraction point in image space. The problem thus reduces to finding the diffraction point in image space, , of the path . According to Fermat’s principle, the diffraction point minimizes the total path length, denoted by . Specifically,
| (29) | ||||
| (30) |
where . For first-order diffraction, this minimization has a closed-form solution (see Annex C).

Once the diffraction point is found in the image space, the refined path vertices , , are determined by backtracking as in the case without diffraction. However, for depths , the algorithm uses the intermediate images of the diffraction point:
| (31) |
in place of in (27). For , is used as in the non-diffraction case. The diffraction point is simply . This process is depicted in Figure 19.

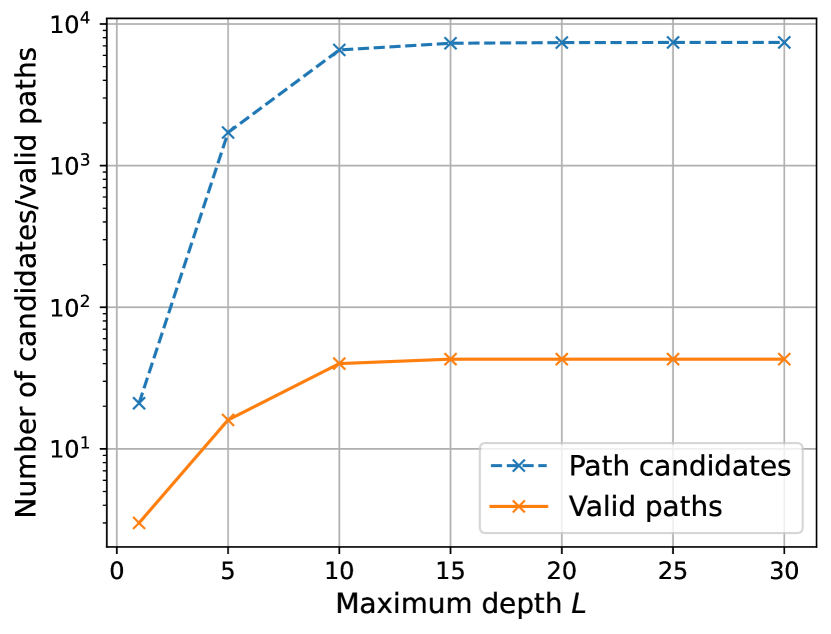
Typically, most of the candidates are discarded by the image method. This is illustrated in Figure 20, which shows the number of candidates discarded as a function of the path depth for a single source and target. The considered scene is shown in Figure 20(a). The number of samples is , diffuse reflection is disabled, and diffraction is enabled. As seen in Figure 20(b), most of the candidates are discarded by the image method because only specular chains are generated by the candidate generator, and most of them do not result in valid paths.
3.3 Channel Coefficients, Delays, and Doppler Shifts Computation
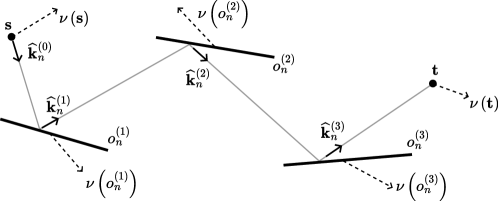
The final step of the path solver computes complex-valued channel coefficients and real-valued delays for each valid path (see Figure 9). For clarity, we will focus our discussion on a single valid path with index and depth , though the same procedure applies to all valid paths computed by both the SBR-based candidate generator and image method. We denote the path vertices as , which may correspond to vertices previously computed by the image method (denoted earlier as ). The directions of propagation between vertices are represented by unit vectors , defined as
| (32) |
where is the source and is the target. Note that these propagation directions may differ from those used during the initial SBR loop described in Section 3.1 due to the refinement by the image method.
Ensuring Energy Conservation
As explained in Section 3.1.2, at each interaction point, an interaction type is randomly chosen based on the probability distribution (19). Initially, the energy emitted by the source is distributed across samples according to the transmit antenna pattern (see Section A.3). Since only one interaction type is selected at each interaction point, ray tubes that do not match the chosen interaction type are discarded, as illustrated in Figure 21. The remaining ray tubes must therefore compensate for the discarded ones to maintain energy conservation. Given that there is a finite number of specular chains with a specific depth, the channel gain (5) observed at the target due to specular chains is accurate if all specular chains are identified by the path solver, which is assumed to be the case. This assumption will be reasonable if the number of samples is sufficiently large.
In the context of diffuse reflections, an incident ray tube scatters an amount of energy that is determined by its footprint on the diffusely reflective surface (see Section A.9). Due to the random sampling of interaction types, only a portion of the ray tubes that should reach a diffusely reflective surface are actually traced (see Figure 21), which requires compensating for the untraced ones. For a given path that includes a diffuse reflection and has a specular suffix index (10), we denote by the probability of sampling the prefix leading to the last diffuse reflection point, where is defined in (19). Consequently, on average, only a fraction of the ray tubes that should reach the diffusely reflective surface are actually traced. To account for this, the electric field is scaled by at the point of diffuse reflection.
Path Coefficient and Delay Computation
Algorithm 2 outlines the computation of the electric field along a path, based on the EM background in Appendix A. The algorithm calculates the electric field vector for each path by iterating through its sequence of interactions. Computation begins by initializing the electric field with the transmit antenna pattern, evaluated in the initial departure direction . For dual polarization, two independent electric field vectors are tracked per path. The variable accumulates the total propagation delay, and tracks the ray tube length; both start at zero. The cumulative path probability , used for energy normalization, is initialized to one (see previous paragraph) and updated at each interaction. The variable is only used for diffracted paths. For these paths, it accumulates the length of the incident ray tube on the diffracting edge, which is required to compute the diffraction spreading factor, i.e., the field intensity decrease factor due to free space propagation (see Section A.8).
At each interaction, the electric field is updated by the transfer matrix , which depends on the intersected object , the interaction type , and other parameters (omitted for brevity). The path probability is multiplied by the current interaction probability . For diffuse reflections, the electric field is divided by to ensure energy conservation and and are reset to one and zero, respectively, as diffuse reflection spawns a new ray tube. For diffractions, the length of the incident ray tube on the diffracting edge is stored in and is reset to zero. Each segment’s travel time is added to , with the speed of light.
After processing all interactions, the algorithm adds the final segment to the target to both and . The receive antenna pattern is then evaluated for the incoming direction, and the channel coefficient is computed following Section A.6. Finally, the spreading factor (lines 25–29) is computed and applied to the channel coefficient depending on whether the path involves diffraction or not.
Remark
The transfer matrices and the electric field vectors are complex-valued, but are implemented using their real-valued representations defined as
| (33) |
for matrices and
| (34) |
for vectors, where and denote the real and imaginary parts, respectively.
3.3.1 Handling Multiple Antennas at the Transmitter and Receiver
As explained in the introduction (Section 1), Sionna RT supports antenna arrays of any size at both the transmitter and receiver, utilizing either synthetic or non-synthetic arrays. In the case of non-synthetic arrays, each transmit antenna is treated as a source and each receive antenna as a target, meaning paths are traced from every transmit antenna, and the solver calculates paths for each transmit-receive antenna pair. For synthetic arrays, paths originate from a single “virtual” source at the center of the transmitter array, and a single “virtual” target is considered at the center of every receiver array. Channel coefficients are then computed by applying phase shifts synthetically. This method allows for efficient scaling with the number of antennas, but it is an approximation that is valid only when the transmitter and receiver array sizes are small relative to the distance from the radio devices to each other and to the scatterers. Formally, for synthetic arrays, the channel matrix for the -th path is expressed as:
| (35) |
where is the channel coefficient for the -th path, calculated using Algorithm 2. The array response vectors for the transmit () and receive () antenna arrays are defined as:
| (36) | ||||
Here, () represents the departure (arrival) direction of the -th path, () denotes the number of antennas in the transmit (receive) array, and () indicates the relative position of the -th antenna element to the virtual source (target) in the transmit (receive) array.
3.3.2 Doppler Shifts
The impact of moving scene objects on the paths can be simulated in two ways. The first approach involves moving objects in small incremental steps along their trajectories and recomputing the propagation paths at each step. While this method provides the highest accuracy, it is computationally expensive. However, when trajectory lengths are small (not exceeding a few wavelengths), a more efficient approach may be used. In this alternative method, we assign a velocity vector to each object and compute the time evolution by accumulating Doppler shifts along the propagation paths.
Figure 22 illustrates this approach. When replaying the valid paths using Algorithm 2, the Doppler shift for each path is computed by accumulating the contributions from individual objects:
| (37) |
where is the wavelength. This results in the total Doppler shift caused by object movements along the path. The final Doppler shift observed at the target combines the accumulated shift from moving objects with the shifts caused by source and target motion:
| (38) |
where and denote the velocity vectors of the source and target, respectively.
3.4 Current Limitations and Potential Improvements
We discuss in this section some current limitations and potential improvements of the path solver.
Sampling of Ray Directions
Improved sample efficiency could be achieved by sampling initial ray directions and scattered ray directions based on the transmit antenna pattern and the scattering pattern, respectively. This approach is motivated by the substantial sample efficiency gains shown in Section 3.1.2 through the use of importance sampling. By applying optimized sampling strategies for ray directions, further improvements may be realized, as illustrated in Figure 23.
Handling Large Numbers of Targets and Sources

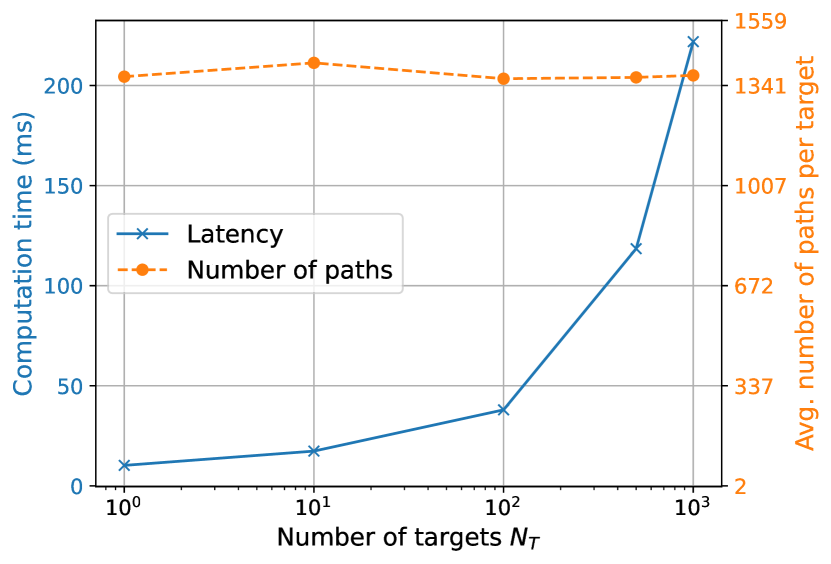
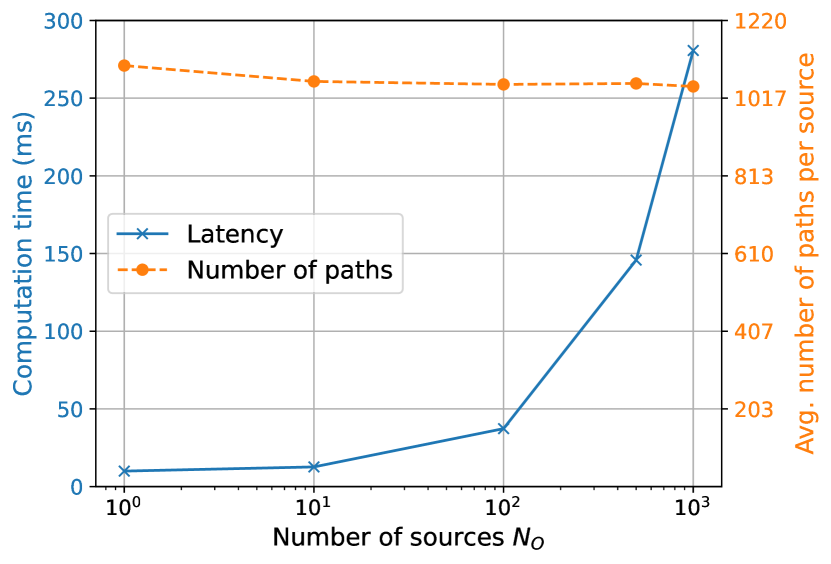
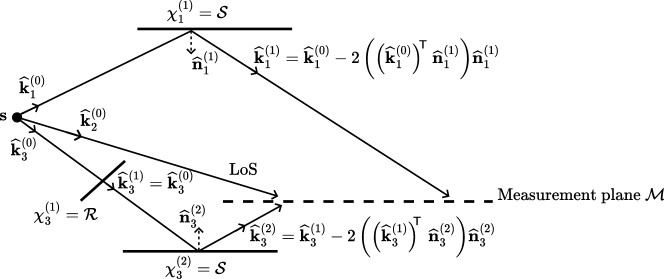
The current method for handling multiple targets involves iterating over all targets during each SBR loop iteration. Figure 24(b) illustrates this, showing the compute time of the candidate generator and the average number of candidates per target found as the number of targets varies. In this experiment, the built-in Sionna RT scene “simple street canyon” depicted in Figure 24(a), was used. Targets were sampled uniformly at random on a plane parallel to the ground at an elevation of 1.5 meters. The maximum depth was set to 5, diffuse reflections were disabled, and the number of samples was set to . As observed, the compute time increases with the number of targets due to the iteration over all targets in each SBR loop iteration. However, the number of candidates per target remains stable, although with variations due to hash collisions. Note that, as discussed in Section 3.2, most candidates do not result in valid paths. This approach may be optimized by selecting only targets near intersection points or the source, which will enhance scalability when dealing with a large number of targets.
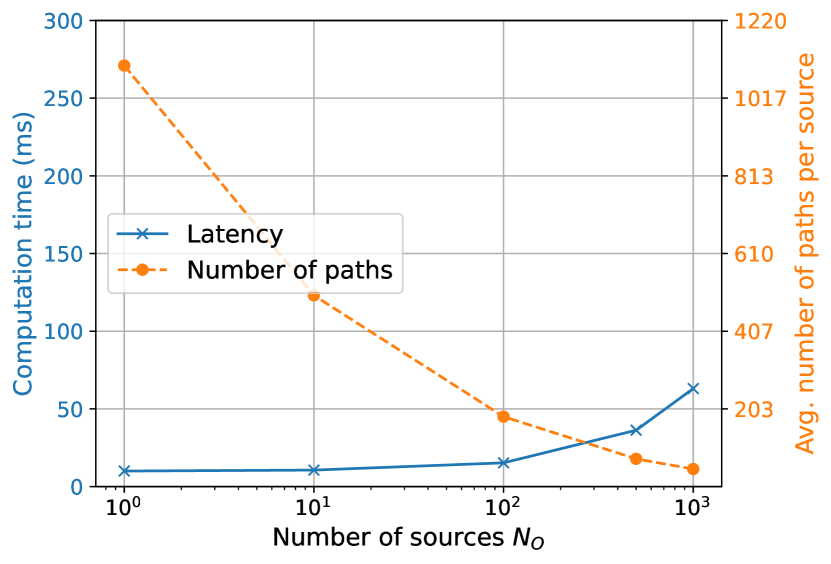
Scaling with the number of sources presents its own set of challenges. When samples are generated per source, the total number of samples produced by the candidate generator becomes , where denotes the number of sources. This results in increased computation time as the number of sources grows, as illustrated in Figure 24(c). However, the number of candidates per source remains stable. In this experiment, a single target is positioned at the center of the scene at an elevation of 1.5 meters, while sources are randomly sampled on a plane parallel to the ground at an elevation of 70 meters, above all buildings. Recall that variations in the number of candidates per source may occur due to collisions. For a comprehensive view, Figure 24(d) presents results where the total number of samples is kept constant at , resulting in samples per source. In this scenario, the computation time increases at a much slower rate with the number of sources, but the number of candidates found per source decreases rapidly as the number of sources increases.
Higher-Order Diffraction and Diffuse Reflection
The path solver supports only first-order diffraction and does not handle paths that contain both diffraction and diffuse reflection. Enabling support for such combined paths would require the refinement of non-suffix path segments, which is computationally expensive and thus not implemented at present. However, these mixed paths typically transport a negligible amount of energy and therefore have little impact on the accuracy of the computed CIRs.
Regarding high-order diffraction, there are algorithms for determining the diffraction vertices [22]. However, calculating the electric field along these high-order diffraction paths remains an open problem, and as a result, high-order diffraction is not currently supported.
Collisions of Specular Chain Candidates
The path solver does not handle collisions of specular chain candidates. More precisely, when two different specular chains share the same index value in the hash array despite having a different hash due to the modulo operation (23), the path solver discards one of them. This could be avoided by using a collision resolution mechanism, and by dynamically adjusting the hash array size to reduce the probability of collisions. Currently, it is assumed that the hash array size is set to a sufficiently large value to make collisions negligible.