Closed Loop Evaluation#
Closed loop evaluation tests a trained mindmap model in Isaac Lab simulation. Observational data is fed to the model in real-time, and the model’s actions are executed in the simulation.
Task Demonstrations#
The following GIFs show mindmap models successfully completing each benchmark task:

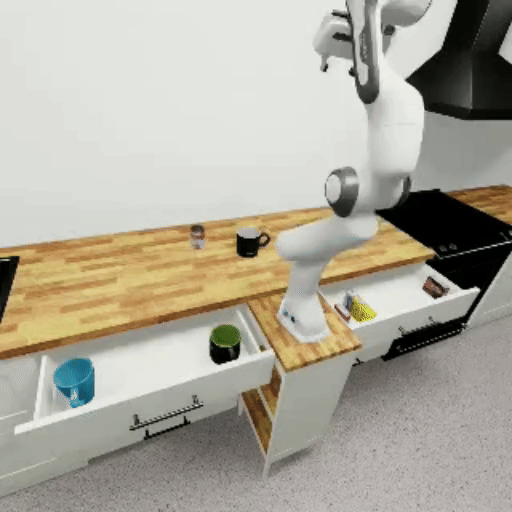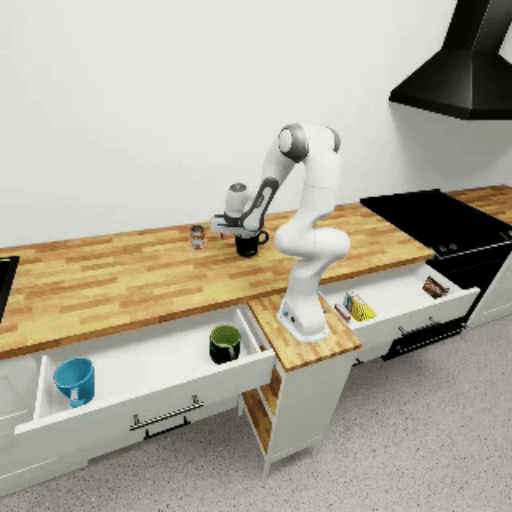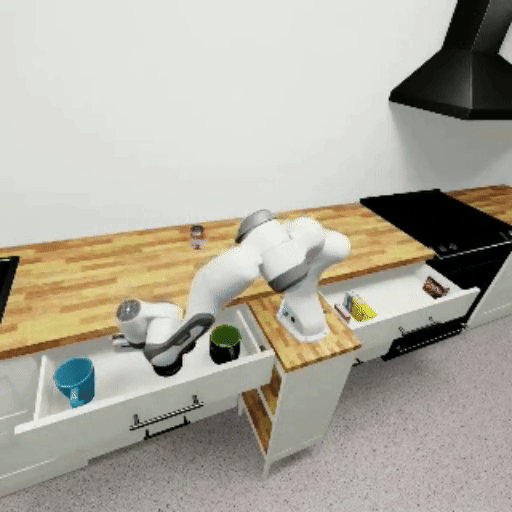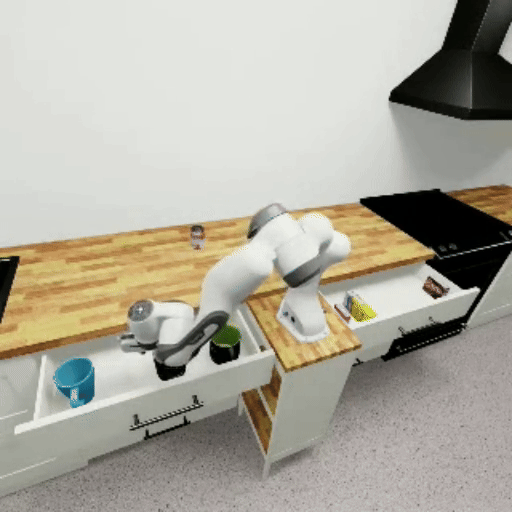


Prerequisites#
Make sure you have set up mindmap and are inside the interactive Docker container.
Obtain HDF5 demonstration files by either:
Obtain a trained model by either:
Running Closed Loop Evaluation#
Evaluate your model on the chosen task:
torchrun_local run_closed_loop_policy.py \
--task cube_stacking \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--checkpoint <LOCAL_CHECKPOINT_PATH>/best.pth \
--demos_closed_loop 150-249 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_franka_cube_stacking_1000_demos.hdf5
torchrun_local run_closed_loop_policy.py \
--task mug_in_drawer \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--checkpoint <LOCAL_CHECKPOINT_PATH>/best.pth \
--demos_closed_loop 150-249 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_franka_mug_in_drawer_250_demos.hdf5
torchrun_local run_closed_loop_policy.py \
--task drill_in_box \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--checkpoint <LOCAL_CHECKPOINT_PATH>/best.pth \
--demos_closed_loop 100-199 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_gr1_drill_in_box_200_demos.hdf5
torchrun_local run_closed_loop_policy.py \
--task stick_in_bin \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--checkpoint <LOCAL_CHECKPOINT_PATH>/best.pth \
--demos_closed_loop 100-199 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_gr1_stick_in_bin_200_demos.hdf5
Note
The selected demos in the commands above correspond to 100 demonstrations each from the evaluation set of the pre-trained models.
Note
Using the --record_videos flag, closed loop evaluation runs can be recorded and stored at the path specified with --record_camera_output_path <VIDEO_OUTPUT_DIR>.
Alternatively, you can evaluate a task in ground truth mode, which replays the ground truth keyposes from a dataset:
torchrun_local run_closed_loop_policy.py \
--task cube_stacking \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--dataset <LOCAL_DATASET_PATH> \
--demos_closed_loop 0-9 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_franka_cube_stacking_1000_demos.hdf5 \
--demo_mode execute_gt_goals
torchrun_local run_closed_loop_policy.py \
--task mug_in_drawer \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--dataset <LOCAL_DATASET_PATH> \
--demos_closed_loop 0-9 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_franka_mug_in_drawer_250_demos.hdf5 \
--demo_mode execute_gt_goals
torchrun_local run_closed_loop_policy.py \
--task drill_in_box \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--dataset <LOCAL_DATASET_PATH> \
--demos_closed_loop 0-9 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_gr1_drill_in_box_200_demos.hdf5 \
--demo_mode execute_gt_goals
torchrun_local run_closed_loop_policy.py \
--task stick_in_bin \
--data_type rgbd_and_mesh \
--feature_type radio_v25_b \
--dataset <LOCAL_DATASET_PATH> \
--demos_closed_loop 0-9 \
--hdf5_file <LOCAL_DATASET_PATH>/mindmap_gr1_stick_in_bin_200_demos.hdf5 \
--demo_mode execute_gt_goals
Running in ground truth mode is useful for validating the keypose extraction pipeline and estimating the model’s maximum achievable performance before training.
Evaluation Results#
After completing all selected demonstrations, check the model’s success rate:
Console output: Look for the lines after
Summary of closed loop evaluationEvaluation file: Check the file specified by
--eval_file_path(if provided)
The success rate indicates how many demonstrations the model completed successfully.
Note
Closed loop evaluation is not deterministic, i.e. the same demonstration can succeed or fail on different runs even if the same model or ground truth goals are used. Therefore, it is important to run enough demonstrations to get a statistically significant result.
Visualization Options#
To visualize model inputs and outputs during evaluation:
Add the
--visualizeflag to your commandSelect a visualization window by clicking on it
Press space to trigger the next inference step
This allows you to observe how the model processes spatial information and makes real-time predictions.
Note
Replace <LOCAL_DATASET_PATH> with your dataset directory path
and <LOCAL_CHECKPOINT_PATH> with your checkpoint directory path.
Note
For more information on parameters choice and available options, see Parameters.