Discover Sionna
This example notebook will guide you through the basic principles and illustrates the key features of Sionna. With only a few commands, you can simulate the PHY-layer link-level performance for many 5G-compliant components, including easy visualization of the results.
Load Required Packages
The Sionna python package must be installed.
[1]:
import os
if os.getenv("CUDA_VISIBLE_DEVICES") is None:
gpu_num = 0 # Use "" to use the CPU
os.environ["CUDA_VISIBLE_DEVICES"] = f"{gpu_num}"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# Import Sionna
try:
import sionna
except ImportError as e:
# Install Sionna if package is not already installed
import os
os.system("pip install sionna")
import sionna
import numpy as np
import tensorflow as tf
# Avoid warnings from TensorFlow
tf.get_logger().setLevel('ERROR')
# IPython "magic function" for inline plots
%matplotlib inline
import matplotlib.pyplot as plt
Tip: you can run bash commands in Jupyter via the ! operator.
[2]:
!nvidia-smi
Thu Sep 26 14:40:00 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:01:00.0 Off | N/A |
| 0% 48C P2 39W / 350W | 292MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:4D:00.0 Off | N/A |
| 30% 42C P8 23W / 350W | 3MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
In case multiple GPUs are available, we restrict this notebook to single-GPU usage. You can ignore this command if only one GPU is available.
Further, we want to avoid that this notebook instantiates the whole GPU memory when initialized and set memory_growth as active.
Remark: Sionna does not require a GPU. Everything can also run on your CPU - but you may need to wait a little longer.
[3]:
# Configure the notebook to use only a single GPU and allocate only as much memory as needed
# For more details, see https://www.tensorflow.org/guide/gpu
gpus = tf.config.list_physical_devices('GPU')
print('Number of GPUs available :', len(gpus))
if gpus:
gpu_num = 0 # Index of the GPU to be used
try:
#tf.config.set_visible_devices([], 'GPU')
tf.config.set_visible_devices(gpus[gpu_num], 'GPU')
print('Only GPU number', gpu_num, 'used.')
tf.config.experimental.set_memory_growth(gpus[gpu_num], True)
except RuntimeError as e:
print(e)
Number of GPUs available : 1
Only GPU number 0 used.
Sionna Data-flow and Design Paradigms
Sionna inherently parallelizes simulations via batching, i.e., each element in the batch dimension is simulated independently.
This means the first tensor dimension is always used for inter-frame parallelization similar to an outer for-loop in Matlab/NumPy simulations.
To keep the dataflow efficient, Sionna follows a few simple design principles:
Signal-processing components are implemented as an individual Keras layer.
tf.float32is used as preferred datatype andtf.complex64for complex-valued datatypes, respectively. This allows simpler re-use of components (e.g., the same scrambling layer can be used for binary inputs and LLR-values).Models can be developed in eager mode allowing simple (and fast) modification of system parameters.
Number crunching simulations can be executed in the faster graph mode or even XLA acceleration is available for most components.
Whenever possible, components are automatically differentiable via auto-grad to simplify the deep learning design-flow.
Code is structured into sub-packages for different tasks such as channel coding, mapping,… (see API documentation for details).
The division into individual blocks simplifies deployment and all layers and functions comes with unittests to ensure their correct behavior.
These paradigms simplify the re-useability and reliability of our components for a wide range of communications related applications.
A note on random number generation
When Sionna is loaded, it instantiates random number generators (RNGs) for Python, NumPy, and TensorFlow. You can optionally set a seed which will make all of your results deterministic, as long as only these RNGs are used. In the cell below, you can see how this seed is set and how the different RNGs can be used.
[4]:
sionna.config.seed = 40
# Python RNG - use instead of
# import random
# random.randint(0, 10)
print(sionna.config.py_rng.randint(0,10))
# NumPy RNG - use instead of
# import numpy as np
# np.random.randint(0, 10)
print(sionna.config.np_rng.integers(0,10))
# TensorFlow RNG - use instead of
# import tensorflow as tf
# tf.random.uniform(shape=[1], minval=0, maxval=10, dtype=tf.int32)
print(sionna.config.tf_rng.uniform(shape=[1], minval=0, maxval=10, dtype=tf.int32))
7
5
tf.Tensor([2], shape=(1,), dtype=int32)
Let’s Get Started - The First Layers (Eager Mode)
Every layer needs to be initialized once before it can be used.
Tip: use the API documentation to find an overview of all existing components.
We now want to transmit some symbols over an AWGN channel. First, we need to initialize the corresponding layer.
[5]:
channel = sionna.channel.AWGN() # init AWGN channel layer
In this first example, we want to add Gaussian noise to some given values of x.
Remember - the first dimension is the batch-dimension.
We simulate 2 message frames each containing 4 symbols.
Remark: the AWGN channel is defined to be complex-valued.
[6]:
# define a (complex-valued) tensor to be transmitted
x = tf.constant([[0., 1.5, 1., 0.],[-1., 0., -2, 3 ]], dtype=tf.complex64)
# let's have look at the shape
print("Shape of x: ", x.shape)
print("Values of x: ", x)
Shape of x: (2, 4)
Values of x: tf.Tensor(
[[ 0. +0.j 1.5+0.j 1. +0.j 0. +0.j]
[-1. +0.j 0. +0.j -2. +0.j 3. +0.j]], shape=(2, 4), dtype=complex64)
We want to simulate the channel at an SNR of 5 dB. For this, we can simply call the previously defined layer channel.
If you have never used Keras you can think of a layer as of a function: it has an input and returns the processed output.
Remark: Each time this cell is executed a new noise realization is drawn.
[7]:
ebno_db = 5
# calculate noise variance from given EbNo
no = sionna.utils.ebnodb2no(ebno_db = ebno_db,
num_bits_per_symbol=2, # QPSK
coderate=1)
y = channel([x, no])
print("Noisy symbols are: ", y)
Noisy symbols are: tf.Tensor(
[[-0.02095131+0.19480924j 1.3121496 +0.05868753j 0.67274046-0.13089974j
-0.303877 +0.19657521j]
[-0.9967893 +0.12435442j -0.5632028 -0.14088595j -1.9711018 -0.3130482j
2.7371373 +0.26847288j]], shape=(2, 4), dtype=complex64)
Batches and Multi-dimensional Tensors
Sionna natively supports multi-dimensional tensors.
Most layers operate at the last dimension and can have arbitrary input shapes (preserved at output).
Let us assume we want to add a CRC-24 check to 64 codewords of length 500 (e.g., different CRC per sub-carrier). Further, we want to parallelize the simulation over a batch of 100 samples.
[8]:
batch_size = 100 # outer level of parallelism
num_codewords = 64 # codewords per batch sample
info_bit_length = 500 # info bits PER codeword
source = sionna.utils.BinarySource() # yields random bits
u = source([batch_size, num_codewords, info_bit_length]) # call the source layer
print("Shape of u: ", u.shape)
# initialize an CRC encoder with the standard compliant "CRC24A" polynomial
encoder_crc = sionna.fec.crc.CRCEncoder("CRC24A")
decoder_crc = sionna.fec.crc.CRCDecoder(encoder_crc) # connect to encoder
# add the CRC to the information bits u
c = encoder_crc(u) # returns a list [c, crc_valid]
print("Shape of c: ", c.shape)
print("Processed bits: ", np.size(c.numpy()))
# we can also verify the results
# returns list of [info bits without CRC bits, indicator if CRC holds]
u_hat, crc_valid = decoder_crc(c)
print("Shape of u_hat: ", u_hat.shape)
print("Shape of crc_valid: ", crc_valid.shape)
print("Valid CRC check of first codeword: ", crc_valid.numpy()[0,0,0])
Shape of u: (100, 64, 500)
Shape of c: (100, 64, 524)
Processed bits: 3353600
Shape of u_hat: (100, 64, 500)
Shape of crc_valid: (100, 64, 1)
Valid CRC check of first codeword: True
We want to do another simulation but for 5 independent users.
Instead of defining 5 different tensors, we can simply add another dimension.
[9]:
num_users = 5
u = source([batch_size, num_users, num_codewords, info_bit_length])
print("New shape of u: ", u.shape)
# We can re-use the same encoder as before
c = encoder_crc(u)
print("New shape of c: ", c.shape)
print("Processed bits: ", np.size(c.numpy()))
New shape of u: (100, 5, 64, 500)
New shape of c: (100, 5, 64, 524)
Processed bits: 16768000
Often a good visualization of results helps to get new research ideas. Thus, Sionna has built-in plotting functions.
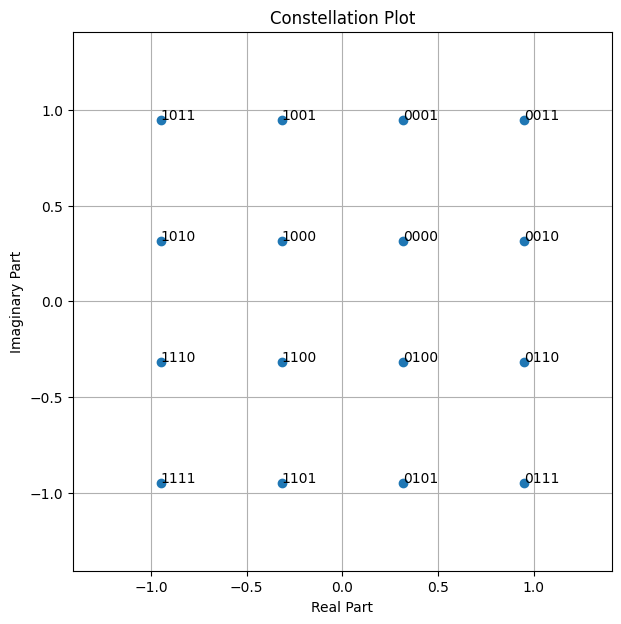
Let’s have look at a 16-QAM constellation.
[10]:
constellation = sionna.mapping.Constellation("qam", num_bits_per_symbol=4)
constellation.show();
First Link-level Simulation
We can already build powerful code with a few simple commands.
As mentioned earlier, Sionna aims at hiding system complexity into Keras layers. However, we still want to provide as much flexibility as possible. Thus, most layers have several choices of init parameters, but often the default choice is a good start.
Tip: the API documentation provides many helpful references and implementation details.
[11]:
# system parameters
n_ldpc = 500 # LDPC codeword length
k_ldpc = 250 # number of info bits per LDPC codeword
coderate = k_ldpc / n_ldpc
num_bits_per_symbol = 4 # number of bits mapped to one symbol (cf. QAM)
Often, several different algorithms are implemented, e.g., the demapper supports “true app” demapping, but also “max-log” demapping.
The check-node (CN) update function of the LDPC BP decoder also supports multiple algorithms.
[12]:
demapping_method = "app" # try "max-log"
ldpc_cn_type = "boxplus" # try also "minsum"
Let us initialize all required components for the given system parameters.
[13]:
binary_source = sionna.utils.BinarySource()
encoder = sionna.fec.ldpc.encoding.LDPC5GEncoder(k_ldpc, n_ldpc)
constellation = sionna.mapping.Constellation("qam", num_bits_per_symbol)
mapper = sionna.mapping.Mapper(constellation=constellation)
channel = sionna.channel.AWGN()
demapper = sionna.mapping.Demapper(demapping_method,
constellation=constellation)
decoder = sionna.fec.ldpc.decoding.LDPC5GDecoder(encoder,
hard_out=True, cn_type=ldpc_cn_type,
num_iter=20)
We can now run the code in eager mode. This allows us to modify the structure at any time - you can try a different batch_size or a different SNR ebno_db.
[14]:
# simulation parameters
batch_size = 1000
ebno_db = 4
# Generate a batch of random bit vectors
b = binary_source([batch_size, k_ldpc])
# Encode the bits using 5G LDPC code
print("Shape before encoding: ", b.shape)
c = encoder(b)
print("Shape after encoding: ", c.shape)
# Map bits to constellation symbols
x = mapper(c)
print("Shape after mapping: ", x.shape)
# Transmit over an AWGN channel at SNR 'ebno_db'
no = sionna.utils.ebnodb2no(ebno_db, num_bits_per_symbol, coderate)
y = channel([x, no])
print("Shape after channel: ", y.shape)
# Demap to LLRs
llr = demapper([y, no])
print("Shape after demapping: ", llr.shape)
# LDPC decoding using 20 BP iterations
b_hat = decoder(llr)
print("Shape after decoding: ", b_hat.shape)
# calculate BERs
c_hat = tf.cast(tf.less(0.0, llr), tf.float32) # hard-decided bits before dec.
ber_uncoded = sionna.utils.metrics.compute_ber(c, c_hat)
ber_coded = sionna.utils.metrics.compute_ber(b, b_hat)
print("BER uncoded = {:.3f} at EbNo = {:.1f} dB".format(ber_uncoded, ebno_db))
print("BER after decoding = {:.3f} at EbNo = {:.1f} dB".format(ber_coded, ebno_db))
print("In total {} bits were simulated".format(np.size(b.numpy())))
Shape before encoding: (1000, 250)
Shape after encoding: (1000, 500)
Shape after mapping: (1000, 125)
Shape after channel: (1000, 125)
Shape after demapping: (1000, 500)
Shape after decoding: (1000, 250)
BER uncoded = 0.119 at EbNo = 4.0 dB
BER after decoding = 0.008 at EbNo = 4.0 dB
In total 250000 bits were simulated
Just to summarize: we have simulated the transmission of 250,000 bits including higher-order modulation and channel coding!
But we can go even faster with the TF graph execution!
Setting up the End-to-end Model
We now define a Keras model that is more convenient for training and Monte-Carlo simulations.
We simulate the transmission over a time-varying multi-path channel (the TDL-A model from 3GPP TR38.901). For this, OFDM and a conventional bit-interleaved coded modulation (BICM) scheme with higher order modulation is used. The information bits are protected by a 5G-compliant LDPC code.
Remark: Due to the large number of parameters, we define them as dictionary.
[15]:
class e2e_model(tf.keras.Model): # inherits from keras.model
"""Example model for end-to-end link-level simulations.
Parameters
----------
params: dict
A dictionary defining the system parameters.
Input
-----
batch_size: int or tf.int
The batch_sizeused for the simulation.
ebno_db: float or tf.float
A float defining the simulation SNR.
Output
------
(b, b_hat):
Tuple:
b: tf.float32
A tensor of shape `[batch_size, k]` containing the transmitted
information bits.
b_hat: tf.float32
A tensor of shape `[batch_size, k]` containing the receiver's
estimate of the transmitted information bits.
"""
def __init__(self,
params):
super().__init__()
# Define an OFDM Resource Grid Object
self.rg = sionna.ofdm.ResourceGrid(
num_ofdm_symbols=params["num_ofdm_symbols"],
fft_size=params["fft_size"],
subcarrier_spacing=params["subcarrier_spacing"],
num_tx=1,
num_streams_per_tx=1,
cyclic_prefix_length=params["cyclic_prefix_length"],
pilot_pattern="kronecker",
pilot_ofdm_symbol_indices=params["pilot_ofdm_symbol_indices"])
# Create a Stream Management object
self.sm = sionna.mimo.StreamManagement(rx_tx_association=np.array([[1]]),
num_streams_per_tx=1)
self.coderate = params["coderate"]
self.num_bits_per_symbol = params["num_bits_per_symbol"]
self.n = int(self.rg.num_data_symbols*self.num_bits_per_symbol)
self.k = int(self.n*coderate)
# Init layers
self.binary_source = sionna.utils.BinarySource()
self.encoder = sionna.fec.ldpc.encoding.LDPC5GEncoder(self.k, self.n)
self.interleaver = sionna.fec.interleaving.RowColumnInterleaver(
row_depth=self.num_bits_per_symbol)
self.deinterleaver = sionna.fec.interleaving.Deinterleaver(self.interleaver)
self.mapper = sionna.mapping.Mapper("qam", self.num_bits_per_symbol)
self.rg_mapper = sionna.ofdm.ResourceGridMapper(self.rg)
self.tdl = sionna.channel.tr38901.TDL(model="A",
delay_spread=params["delay_spread"],
carrier_frequency=params["carrier_frequency"],
min_speed=params["min_speed"],
max_speed=params["max_speed"])
self.channel = sionna.channel.OFDMChannel(self.tdl, self.rg, add_awgn=True, normalize_channel=True)
self.ls_est = sionna.ofdm.LSChannelEstimator(self.rg, interpolation_type="nn")
self.lmmse_equ = sionna.ofdm.LMMSEEqualizer(self.rg, self.sm)
self.demapper = sionna.mapping.Demapper(params["demapping_method"],
"qam", self.num_bits_per_symbol)
self.decoder = sionna.fec.ldpc.decoding.LDPC5GDecoder(self.encoder,
hard_out=True,
cn_type=params["cn_type"],
num_iter=params["bp_iter"])
print("Number of pilots: {}".format(self.rg.num_pilot_symbols))
print("Number of data symbols: {}".format(self.rg.num_data_symbols))
print("Number of resource elements: {}".format(
self.rg.num_resource_elements))
print("Pilot overhead: {:.2f}%".format(
self.rg.num_pilot_symbols /
self.rg.num_resource_elements*100))
print("Cyclic prefix overhead: {:.2f}%".format(
params["cyclic_prefix_length"] /
(params["cyclic_prefix_length"]
+params["fft_size"])*100))
print("Each frame contains {} information bits".format(self.k))
def call(self, batch_size, ebno_db):
# Generate a batch of random bit vectors
# We need two dummy dimension representing the number of
# transmitters and streams per transmitter, respectively.
b = self.binary_source([batch_size, 1, 1, self.k])
# Encode the bits using the all-zero dummy encoder
c = self.encoder(b)
# Interleave the bits before mapping (BICM)
c_int = self.interleaver(c)
# Map bits to constellation symbols
s = self.mapper(c_int)
# Map symbols onto OFDM ressource grid
x_rg = self.rg_mapper(s)
# Transmit over noisy multi-path channel
no = sionna.utils.ebnodb2no(ebno_db, self.num_bits_per_symbol, self.coderate, self.rg)
y = self.channel([x_rg, no])
# LS Channel estimation with nearest pilot interpolation
h_hat, err_var = self.ls_est ([y, no])
# LMMSE Equalization
x_hat, no_eff = self.lmmse_equ([y, h_hat, err_var, no])
# Demap to LLRs
llr = self.demapper([x_hat, no_eff])
# Deinterleave before decoding
llr_int = self.deinterleaver(llr)
# Decode
b_hat = self.decoder(llr_int)
# number of simulated bits
nb_bits = batch_size*self.k
# transmitted bits and the receiver's estimate after decoding
return b, b_hat
Let us define the system parameters for our simulation as dictionary:
[16]:
sys_params = {
# Channel
"carrier_frequency" : 3.5e9,
"delay_spread" : 100e-9,
"min_speed" : 3,
"max_speed" : 3,
"tdl_model" : "A",
# OFDM
"fft_size" : 256,
"subcarrier_spacing" : 30e3,
"num_ofdm_symbols" : 14,
"cyclic_prefix_length" : 16,
"pilot_ofdm_symbol_indices" : [2, 11],
# Code & Modulation
"coderate" : 0.5,
"num_bits_per_symbol" : 4,
"demapping_method" : "app",
"cn_type" : "boxplus",
"bp_iter" : 20
}
…and initialize the model:
[17]:
model = e2e_model(sys_params)
Number of pilots: 512
Number of data symbols: 3072
Number of resource elements: 3584
Pilot overhead: 14.29%
Cyclic prefix overhead: 5.88%
Each frame contains 6144 information bits
As before, we can simply call the model to simulate the BER for the given simulation parameters.
[18]:
#simulation parameters
ebno_db = 10
batch_size = 200
# and call the model
b, b_hat = model(batch_size, ebno_db)
ber = sionna.utils.metrics.compute_ber(b, b_hat)
nb_bits = np.size(b.numpy())
print("BER: {:.4} at Eb/No of {} dB and {} simulated bits".format(ber.numpy(), ebno_db, nb_bits))
BER: 0.001245 at Eb/No of 10 dB and 1228800 simulated bits
Run some Throughput Tests (Graph Mode)
Sionna is not just an easy-to-use library, but also incredibly fast. Let us measure the throughput of the model defined above.
We compare eager and graph execution modes (see Tensorflow Doc for details), as well as eager with XLA (see https://www.tensorflow.org/xla#enable_xla_for_tensorflow_models). Note that we need to activate the sionna.config.xla_compat feature for XLA to work.
Tip: change the batch_size to see how the batch parallelism enhances the throughput. Depending on your machine, the batch_size may be too large.
[19]:
import time # this block requires the timeit library
batch_size = 200
ebno_db = 5 # evalaute SNR point
repetitions = 4 # throughput is averaged over multiple runs
def get_throughput(batch_size, ebno_db, model, repetitions=1):
""" Simulate throughput in bit/s per ebno_db point.
The results are average over `repetition` trials.
Input
-----
batch_size: int or tf.int32
Batch-size for evaluation.
ebno_db: float or tf.float32
A tensor containing the SNR points be evaluated
model:
Function or model that yields the transmitted bits `u` and the
receiver's estimate `u_hat` for a given ``batch_size`` and
``ebno_db``.
repetitions: int
An integer defining how many trails of the throughput
simulation are averaged.
"""
# call model once to be sure it is compile properly
# otherwise time to build graph is measured as well.
u, u_hat = model(tf.constant(batch_size, tf.int32),
tf.constant(ebno_db, tf.float32))
t_start = time.perf_counter()
# average over multiple runs
for _ in range(repetitions):
u, u_hat = model(tf.constant(batch_size, tf.int32),
tf.constant(ebno_db, tf. float32))
t_stop = time.perf_counter()
# throughput in bit/s
throughput = np.size(u.numpy())*repetitions / (t_stop - t_start)
return throughput
# eager mode - just call the model
def run_eager(batch_size, ebno_db):
return model(batch_size, ebno_db)
time_eager = get_throughput(batch_size, ebno_db, run_eager, repetitions=4)
# the decorator "@tf.function" enables the graph mode
@tf.function
def run_graph(batch_size, ebno_db):
return model(batch_size, ebno_db)
time_graph = get_throughput(batch_size, ebno_db, run_graph, repetitions=4)
# the decorator "@tf.function(jit_compile=True)" enables the graph mode with XLA
# we need to activate the sionna.config.xla_compat feature for this to work
sionna.config.xla_compat=True
@tf.function(jit_compile=True)
def run_graph_xla(batch_size, ebno_db):
return model(batch_size, ebno_db)
time_graph_xla = get_throughput(batch_size, ebno_db, run_graph_xla, repetitions=4)
# we deactivate the sionna.config.xla_compat so that the cell can be run mutiple times
sionna.config.xla_compat=False
print(f"Throughput in eager execution: {time_eager/1e6:.2f} Mb/s")
print(f"Throughput in graph execution: {time_graph/1e6:.2f} Mb/s")
print(f"Throughput in graph execution with XLA: {time_graph_xla/1e6:.2f} Mb/s")
XLA can lead to reduced numerical precision. Use with care.
Throughput in eager execution: 1.56 Mb/s
Throughput in graph execution: 7.76 Mb/s
Throughput in graph execution with XLA: 57.66 Mb/s
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1727361629.171516 312981 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
Obviously, graph execution (with XLA) yields much higher throughputs (at least if a fast GPU is available). Thus, for exhaustive training and Monte-Carlo simulations the graph mode (with XLA and GPU acceleration) is the preferred choice.
Bit-Error Rate (BER) Monte-Carlo Simulations
Monte-Carlo simulations are omnipresent in todays communications research and development. Due its performant implementation, Sionna can be directly used to simulate BER at a performance that competes with compiled languages – but still keeps the flexibility of a script language.
[20]:
ebno_dbs = np.arange(0, 15, 1.)
batch_size = 200 # reduce in case you receive an out-of-memory (OOM) error
max_mc_iter = 1000 # max number of Monte-Carlo iterations before going to next SNR point
num_target_block_errors = 500 # continue with next SNR point after target number of block errors
# we use the built-in ber simulator function from Sionna which uses and early stop after reaching num_target_errors
sionna.config.xla_compat=True
ber_mc,_ = sionna.utils.sim_ber(run_graph_xla, # you can also evaluate the model directly
ebno_dbs,
batch_size=batch_size,
num_target_block_errors=num_target_block_errors,
max_mc_iter=max_mc_iter,
verbose=True) # print status and summary
sionna.config.xla_compat=False
XLA can lead to reduced numerical precision. Use with care.
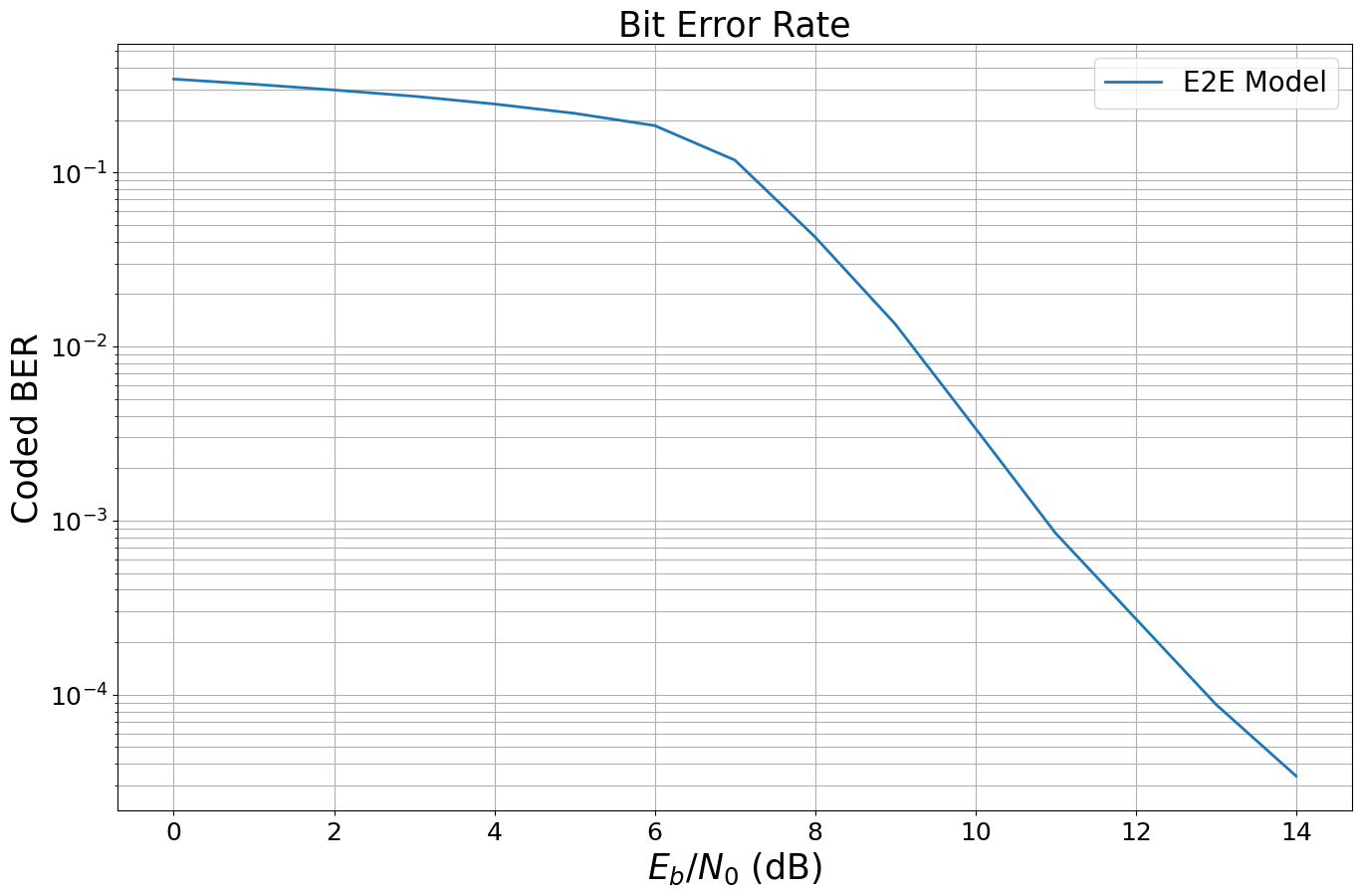
EbNo [dB] | BER | BLER | bit errors | num bits | block errors | num blocks | runtime [s] | status
---------------------------------------------------------------------------------------------------------------------------------------
0.0 | 3.4352e-01 | 1.0000e+00 | 1266347 | 3686400 | 600 | 600 | 0.1 |reached target block errors
1.0 | 3.2095e-01 | 1.0000e+00 | 1183166 | 3686400 | 600 | 600 | 0.1 |reached target block errors
2.0 | 2.9738e-01 | 1.0000e+00 | 1096268 | 3686400 | 600 | 600 | 0.1 |reached target block errors
3.0 | 2.7369e-01 | 1.0000e+00 | 1008918 | 3686400 | 600 | 600 | 0.1 |reached target block errors
4.0 | 2.4703e-01 | 1.0000e+00 | 910649 | 3686400 | 600 | 600 | 0.1 |reached target block errors
5.0 | 2.1839e-01 | 1.0000e+00 | 805067 | 3686400 | 600 | 600 | 0.1 |reached target block errors
6.0 | 1.8570e-01 | 1.0000e+00 | 684560 | 3686400 | 600 | 600 | 0.1 |reached target block errors
7.0 | 1.1760e-01 | 9.9167e-01 | 433539 | 3686400 | 595 | 600 | 0.1 |reached target block errors
8.0 | 4.2571e-02 | 4.7833e-01 | 313870 | 7372800 | 574 | 1200 | 0.2 |reached target block errors
9.0 | 1.3462e-02 | 1.5206e-01 | 281220 | 20889600 | 517 | 3400 | 0.4 |reached target block errors
10.0 | 3.3929e-03 | 3.5352e-02 | 296011 | 87244800 | 502 | 14200 | 1.8 |reached target block errors
11.0 | 8.4720e-04 | 9.1758e-03 | 284203 | 335462400 | 501 | 54600 | 6.8 |reached target block errors
12.0 | 2.7327e-04 | 2.9002e-03 | 289455 | 1059225600 | 500 | 172400 | 21.3 |reached target block errors
13.0 | 8.8057e-05 | 8.9500e-04 | 108205 | 1228800000 | 179 | 200000 | 24.5 |reached max iter
14.0 | 3.4128e-05 | 3.3500e-04 | 41936 | 1228800000 | 67 | 200000 | 24.5 |reached max iter
Let’s look at the results.
[21]:
sionna.utils.plotting.plot_ber(ebno_dbs,
ber_mc,
legend="E2E Model",
ylabel="Coded BER");
Conclusion
We hope you are excited about Sionna - there is much more to be discovered:
TensorBoard debugging available
Scaling to multi-GPU simulation is simple
See the available tutorials for more advanced examples.
And if something is still missing - the project is open-source: you can modify, add, and extend any component at any time.