Part 1: Getting Started with Sionna
This tutorial will guide you through Sionna, from its basic principles to the implementation of a point-to-point link with a 5G NR compliant code and a 3GPP channel model. You will also learn how to write custom trainable layers by implementing a state of the art neural receiver, and how to train and evaluate end-to-end communication systems.
The tutorial is structured in four notebooks:
Part I: Getting started with Sionna
Part II: Differentiable Communication Systems
Part III: Advanced Link-level Simulations
Part IV: Toward Learned Receivers
The official documentation provides key material on how to use Sionna and how its components are implemented.
Imports & Basics
[1]:
import os # Configure which GPU
if os.getenv("CUDA_VISIBLE_DEVICES") is None:
gpu_num = 0 # Use "" to use the CPU
os.environ["CUDA_VISIBLE_DEVICES"] = f"{gpu_num}"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# Import Sionna
try:
import sionna as sn
except ImportError as e:
# Install Sionna if package is not already installed
import os
os.system("pip install sionna")
import sionna as sn
# Configure the notebook to use only a single GPU and allocate only as much memory as needed
# For more details, see https://www.tensorflow.org/guide/gpu
import tensorflow as tf
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
tf.config.experimental.set_memory_growth(gpus[0], True)
except RuntimeError as e:
print(e)
# Avoid warnings from TensorFlow
tf.get_logger().setLevel('ERROR')
import numpy as np
# For plotting
%matplotlib inline
# also try %matplotlib widget
import matplotlib.pyplot as plt
# for performance measurements
import time
# For the implementation of the Keras models
from tensorflow.keras import Model
We can now access Sionna functions within the sn namespace.
Hint: In Jupyter notebooks, you can run bash commands with !.
[2]:
!nvidia-smi
Thu Sep 26 09:11:01 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:01:00.0 Off | N/A |
| 48% 67C P2 193W / 350W | 20356MiB / 24576MiB | 48% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:4D:00.0 Off | N/A |
| 0% 40C P2 102W / 350W | 292MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
A note on random number generation
When Sionna is loaded, it instantiates random number generators (RNGs) for Python, NumPy, and TensorFlow. You can optionally set a seed which will make all of your results deterministic, as long as only these RNGs are used. In the cell below, you can see how this seed is set and how the different RNGs can be used.
[3]:
sn.config.seed = 40
# Python RNG - use instead of
# import random
# random.randint(0, 10)
print(sn.config.py_rng.randint(0,10))
# NumPy RNG - use instead of
# import numpy as np
# np.random.randint(0, 10)
print(sn.config.np_rng.integers(0,10))
# TensorFlow RNG - use instead of
# import tensorflow as tf
# tf.random.uniform(shape=[1], minval=0, maxval=10, dtype=tf.int32)
print(sn.config.tf_rng.uniform(shape=[1], minval=0, maxval=10, dtype=tf.int32))
7
5
tf.Tensor([2], shape=(1,), dtype=int32)
Sionna Data-flow and Design Paradigms
Sionna inherently parallelizes simulations via batching, i.e., each element in the batch dimension is simulated independently.
This means the first tensor dimension is always used for inter-frame parallelization similar to an outer for-loop in Matlab/NumPy simulations, but operations can be operated in parallel.
To keep the dataflow efficient, Sionna follows a few simple design principles:
Signal-processing components are implemented as an individual Keras layer.
tf.float32is used as preferred datatype andtf.complex64for complex-valued datatypes, respectively. This allows simpler re-use of components (e.g., the same scrambling layer can be used for binary inputs and LLR-values).tf.float64/tf.complex128are available when high precision is needed.Models can be developed in eager mode allowing simple (and fast) modification of system parameters.
Number crunching simulations can be executed in the faster graph mode or even XLA acceleration (experimental) is available for most components.
Whenever possible, components are automatically differentiable via auto-grad to simplify the deep learning design-flow.
Code is structured into sub-packages for different tasks such as channel coding, mapping,… (see API documentation for details).
These paradigms simplify the re-useability and reliability of our components for a wide range of communications related applications.
Hello, Sionna!
Let’s start with a very simple simulation: Transmitting QAM symbols over an AWGN channel. We will implement the system shown in the figure below.

We will use upper case for naming simulation parameters that are used throughout this notebook
Every layer needs to be initialized once before it can be used.
Tip: Use the API documentation to find an overview of all existing components. You can directly access the signature and the docstring within jupyter via Shift+TAB.
Remark: Most layers are defined to be complex-valued.
We first need to create a QAM constellation.
[4]:
NUM_BITS_PER_SYMBOL = 2 # QPSK
constellation = sn.mapping.Constellation("qam", NUM_BITS_PER_SYMBOL)
constellation.show();
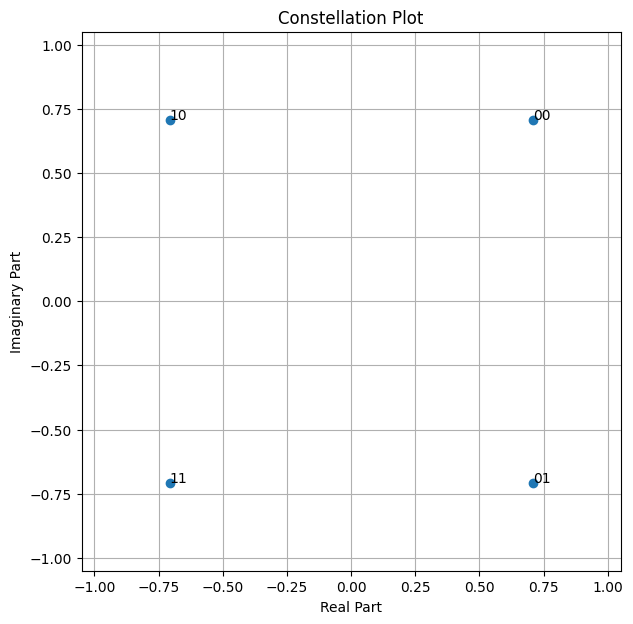
Task: Try to change the modulation order, e.g., to 16-QAM.
We then need to setup a mapper to map bits into constellation points. The mapper takes as parameter the constellation.
We also need to setup a corresponding demapper to compute log-likelihood ratios (LLRs) from received noisy samples.
[5]:
mapper = sn.mapping.Mapper(constellation=constellation)
# The demapper uses the same constellation object as the mapper
demapper = sn.mapping.Demapper("app", constellation=constellation)
Tip: You can access the signature+docstring via ? command and print the complete class definition via ?? operator.
Obviously, you can also access the source code via https://github.com/nvlabs/sionna/.
[6]:
# print class definition of the Constellation class
sn.mapping.Mapper??
Init signature:
sn.mapping.Mapper(
constellation_type=None,
num_bits_per_symbol=None,
constellation=None,
return_indices=False,
dtype=tf.complex64,
**kwargs,
)
Source:
class Mapper(Layer):
# pylint: disable=line-too-long
r"""
Mapper(constellation_type=None, num_bits_per_symbol=None, constellation=None, return_indices=False, dtype=tf.complex64, **kwargs)
Maps binary tensors to points of a constellation.
This class defines a layer that maps a tensor of binary values
to a tensor of points from a provided constellation.
Parameters
----------
constellation_type : One of ["qam", "pam", "custom"], str
For "custom", an instance of :class:`~sionna.mapping.Constellation`
must be provided.
num_bits_per_symbol : int
The number of bits per constellation symbol, e.g., 4 for QAM16.
Only required for ``constellation_type`` in ["qam", "pam"].
constellation : Constellation
An instance of :class:`~sionna.mapping.Constellation` or
`None`. In the latter case, ``constellation_type``
and ``num_bits_per_symbol`` must be provided.
return_indices : bool
If enabled, symbol indices are additionally returned.
Defaults to `False`.
dtype : One of [tf.complex64, tf.complex128], tf.DType
The output dtype. Defaults to tf.complex64.
Input
-----
: [..., n], tf.float or tf.int
Tensor with with binary entries.
Output
------
: [...,n/Constellation.num_bits_per_symbol], tf.complex
The mapped constellation symbols.
: [...,n/Constellation.num_bits_per_symbol], tf.int32
The symbol indices corresponding to the constellation symbols.
Only returned if ``return_indices`` is set to True.
Note
----
The last input dimension must be an integer multiple of the
number of bits per constellation symbol.
"""
def __init__(self,
constellation_type=None,
num_bits_per_symbol=None,
constellation=None,
return_indices=False,
dtype=tf.complex64,
**kwargs
):
super().__init__(dtype=dtype, **kwargs)
assert dtype in [tf.complex64, tf.complex128],\
"dtype must be tf.complex64 or tf.complex128"
# Create constellation object
self._constellation = Constellation.create_or_check_constellation(
constellation_type,
num_bits_per_symbol,
constellation,
dtype=dtype)
self._return_indices = return_indices
self._binary_base = 2**tf.constant(
range(self.constellation.num_bits_per_symbol-1,-1,-1))
@property
def constellation(self):
"""The Constellation used by the Mapper."""
return self._constellation
def call(self, inputs):
tf.debugging.assert_greater_equal(tf.rank(inputs), 2,
message="The input must have at least rank 2")
# Reshape inputs to the desired format
new_shape = [-1] + inputs.shape[1:-1].as_list() + \
[int(inputs.shape[-1] / self.constellation.num_bits_per_symbol),
self.constellation.num_bits_per_symbol]
inputs_reshaped = tf.cast(tf.reshape(inputs, new_shape), tf.int32)
# Convert the last dimension to an integer
int_rep = tf.reduce_sum(inputs_reshaped * self._binary_base, axis=-1)
# Map integers to constellation symbols
x = tf.gather(self.constellation.points, int_rep, axis=0)
if self._return_indices:
return x, int_rep
else:
return x
File: ~/.local/lib/python3.10/site-packages/sionna/mapping.py
Type: type
Subclasses:
As can be seen, the Mapper class inherits from Layer, i.e., implements a Keras layer.
This allows to simply build complex systems by using the Keras functional API to stack layers.
Sionna provides as utility a binary source to sample uniform i.i.d. bits.
[7]:
binary_source = sn.utils.BinarySource()
Finally, we need the AWGN channel.
[8]:
awgn_channel = sn.channel.AWGN()
Sionna provides a utility function to compute the noise power spectral density ratio \(N_0\) from the energy per bit to noise power spectral density ratio \(E_b/N_0\) in dB and a variety of parameters such as the coderate and the nunber of bits per symbol.
[9]:
no = sn.utils.ebnodb2no(ebno_db=10.0,
num_bits_per_symbol=NUM_BITS_PER_SYMBOL,
coderate=1.0) # Coderate set to 1 as we do uncoded transmission here
We now have all the components we need to transmit QAM symbols over an AWGN channel.
Sionna natively supports multi-dimensional tensors.
Most layers operate at the last dimension and can have arbitrary input shapes (preserved at output).
[10]:
BATCH_SIZE = 64 # How many examples are processed by Sionna in parallel
bits = binary_source([BATCH_SIZE,
1024]) # Blocklength
print("Shape of bits: ", bits.shape)
x = mapper(bits)
print("Shape of x: ", x.shape)
y = awgn_channel([x, no])
print("Shape of y: ", y.shape)
llr = demapper([y, no])
print("Shape of llr: ", llr.shape)
Shape of bits: (64, 1024)
Shape of x: (64, 512)
Shape of y: (64, 512)
Shape of llr: (64, 1024)
In Eager mode, we can directly access the values of each tensor. This simplifies debugging.
[11]:
num_samples = 8 # how many samples shall be printed
num_symbols = int(num_samples/NUM_BITS_PER_SYMBOL)
print(f"First {num_samples} transmitted bits: {bits[0,:num_samples]}")
print(f"First {num_symbols} transmitted symbols: {np.round(x[0,:num_symbols], 2)}")
print(f"First {num_symbols} received symbols: {np.round(y[0,:num_symbols], 2)}")
print(f"First {num_samples} demapped llrs: {np.round(llr[0,:num_samples], 2)}")
First 8 transmitted bits: [1. 0. 0. 0. 0. 1. 0. 0.]
First 4 transmitted symbols: [-0.71+0.71j 0.71+0.71j 0.71-0.71j 0.71+0.71j]
First 4 received symbols: [-0.89+0.69j 0.79+0.66j 0.98-0.68j 0.73+0.71j]
First 8 demapped llrs: [ 50.15 -39.18 -44.58 -37.22 -55.23 38.73 -41.16 -39.93]
Let’s visualize the received noisy samples.
[12]:
plt.figure(figsize=(8,8))
plt.axes().set_aspect(1)
plt.grid(True)
plt.title('Channel output')
plt.xlabel('Real Part')
plt.ylabel('Imaginary Part')
plt.scatter(tf.math.real(y), tf.math.imag(y))
plt.tight_layout()
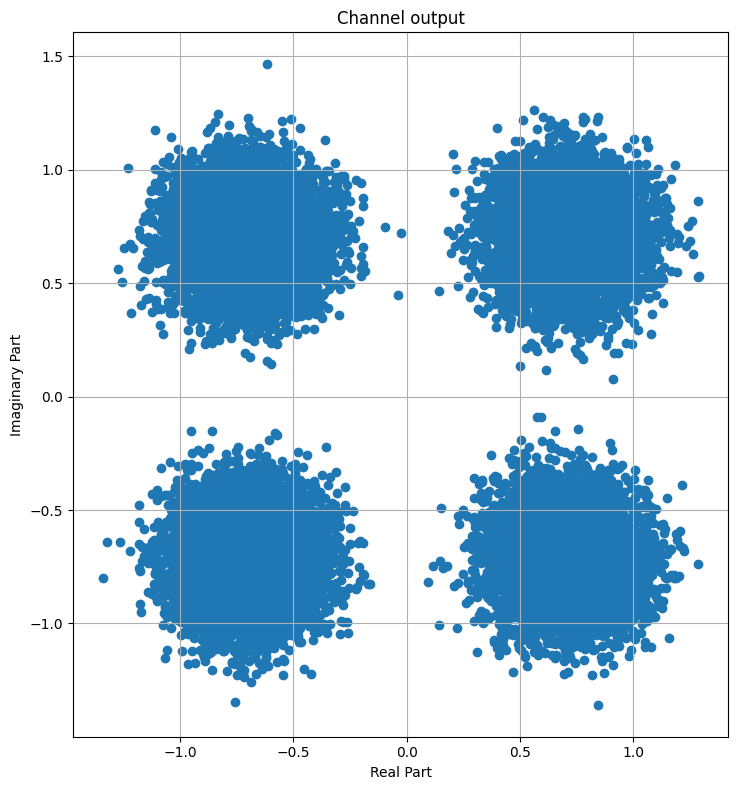
Task: One can play with the SNR to visualize the impact on the received samples.
Advanced Task: Compare the LLR distribution for “app” demapping with “maxlog” demapping. The Bit-Interleaved Coded Modulation example notebook can be helpful for this task.
Communication Systems as Keras Models
It is typically more convenient to wrap a Sionna-based communication system into a Keras model.
These models can be simply built by using the Keras functional API to stack layers.
The following cell implements the previous system as a Keras model.
The key functions that need to be defined are __init__(), which instantiates the required components, and __call()__, which performs forward pass through the end-to-end system.
[13]:
class UncodedSystemAWGN(Model): # Inherits from Keras Model
def __init__(self, num_bits_per_symbol, block_length):
"""
A keras model of an uncoded transmission over the AWGN channel.
Parameters
----------
num_bits_per_symbol: int
The number of bits per constellation symbol, e.g., 4 for QAM16.
block_length: int
The number of bits per transmitted message block (will be the codeword length later).
Input
-----
batch_size: int
The batch_size of the Monte-Carlo simulation.
ebno_db: float
The `Eb/No` value (=rate-adjusted SNR) in dB.
Output
------
(bits, llr):
Tuple:
bits: tf.float32
A tensor of shape `[batch_size, block_length] of 0s and 1s
containing the transmitted information bits.
llr: tf.float32
A tensor of shape `[batch_size, block_length] containing the
received log-likelihood-ratio (LLR) values.
"""
super().__init__() # Must call the Keras model initializer
self.num_bits_per_symbol = num_bits_per_symbol
self.block_length = block_length
self.constellation = sn.mapping.Constellation("qam", self.num_bits_per_symbol)
self.mapper = sn.mapping.Mapper(constellation=self.constellation)
self.demapper = sn.mapping.Demapper("app", constellation=self.constellation)
self.binary_source = sn.utils.BinarySource()
self.awgn_channel = sn.channel.AWGN()
# @tf.function # Enable graph execution to speed things up
def __call__(self, batch_size, ebno_db):
# no channel coding used; we set coderate=1.0
no = sn.utils.ebnodb2no(ebno_db,
num_bits_per_symbol=self.num_bits_per_symbol,
coderate=1.0)
bits = self.binary_source([batch_size, self.block_length]) # Blocklength set to 1024 bits
x = self.mapper(bits)
y = self.awgn_channel([x, no])
llr = self.demapper([y,no])
return bits, llr
We need first to instantiate the model.
[14]:
model_uncoded_awgn = UncodedSystemAWGN(num_bits_per_symbol=NUM_BITS_PER_SYMBOL, block_length=1024)
Sionna provides a utility to easily compute and plot the bit error rate (BER).
[15]:
EBN0_DB_MIN = -3.0 # Minimum value of Eb/N0 [dB] for simulations
EBN0_DB_MAX = 5.0 # Maximum value of Eb/N0 [dB] for simulations
BATCH_SIZE = 2000 # How many examples are processed by Sionna in parallel
ber_plots = sn.utils.PlotBER("AWGN")
ber_plots.simulate(model_uncoded_awgn,
ebno_dbs=np.linspace(EBN0_DB_MIN, EBN0_DB_MAX, 20),
batch_size=BATCH_SIZE,
num_target_block_errors=100, # simulate until 100 block errors occured
legend="Uncoded",
soft_estimates=True,
max_mc_iter=100, # run 100 Monte-Carlo simulations (each with batch_size samples)
show_fig=True);
EbNo [dB] | BER | BLER | bit errors | num bits | block errors | num blocks | runtime [s] | status
---------------------------------------------------------------------------------------------------------------------------------------
-3.0 | 1.5806e-01 | 1.0000e+00 | 323698 | 2048000 | 2000 | 2000 | 0.1 |reached target block errors
-2.579 | 1.4673e-01 | 1.0000e+00 | 300503 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
-2.158 | 1.3499e-01 | 1.0000e+00 | 276463 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
-1.737 | 1.2345e-01 | 1.0000e+00 | 252831 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
-1.316 | 1.1180e-01 | 1.0000e+00 | 228960 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
-0.895 | 1.0129e-01 | 1.0000e+00 | 207442 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
-0.474 | 9.0589e-02 | 1.0000e+00 | 185527 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
-0.053 | 7.9652e-02 | 1.0000e+00 | 163127 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
0.368 | 6.9911e-02 | 1.0000e+00 | 143178 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
0.789 | 6.0820e-02 | 1.0000e+00 | 124560 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
1.211 | 5.2066e-02 | 1.0000e+00 | 106631 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
1.632 | 4.4058e-02 | 1.0000e+00 | 90230 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
2.053 | 3.6521e-02 | 1.0000e+00 | 74795 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
2.474 | 2.9968e-02 | 1.0000e+00 | 61374 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
2.895 | 2.4220e-02 | 1.0000e+00 | 49602 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
3.316 | 1.8940e-02 | 1.0000e+00 | 38790 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
3.737 | 1.4792e-02 | 1.0000e+00 | 30294 | 2048000 | 2000 | 2000 | 0.0 |reached target block errors
4.158 | 1.1268e-02 | 9.9950e-01 | 23077 | 2048000 | 1999 | 2000 | 0.0 |reached target block errors
4.579 | 8.3135e-03 | 9.9950e-01 | 17026 | 2048000 | 1999 | 2000 | 0.0 |reached target block errors
5.0 | 5.9688e-03 | 9.9600e-01 | 12224 | 2048000 | 1992 | 2000 | 0.0 |reached target block errors
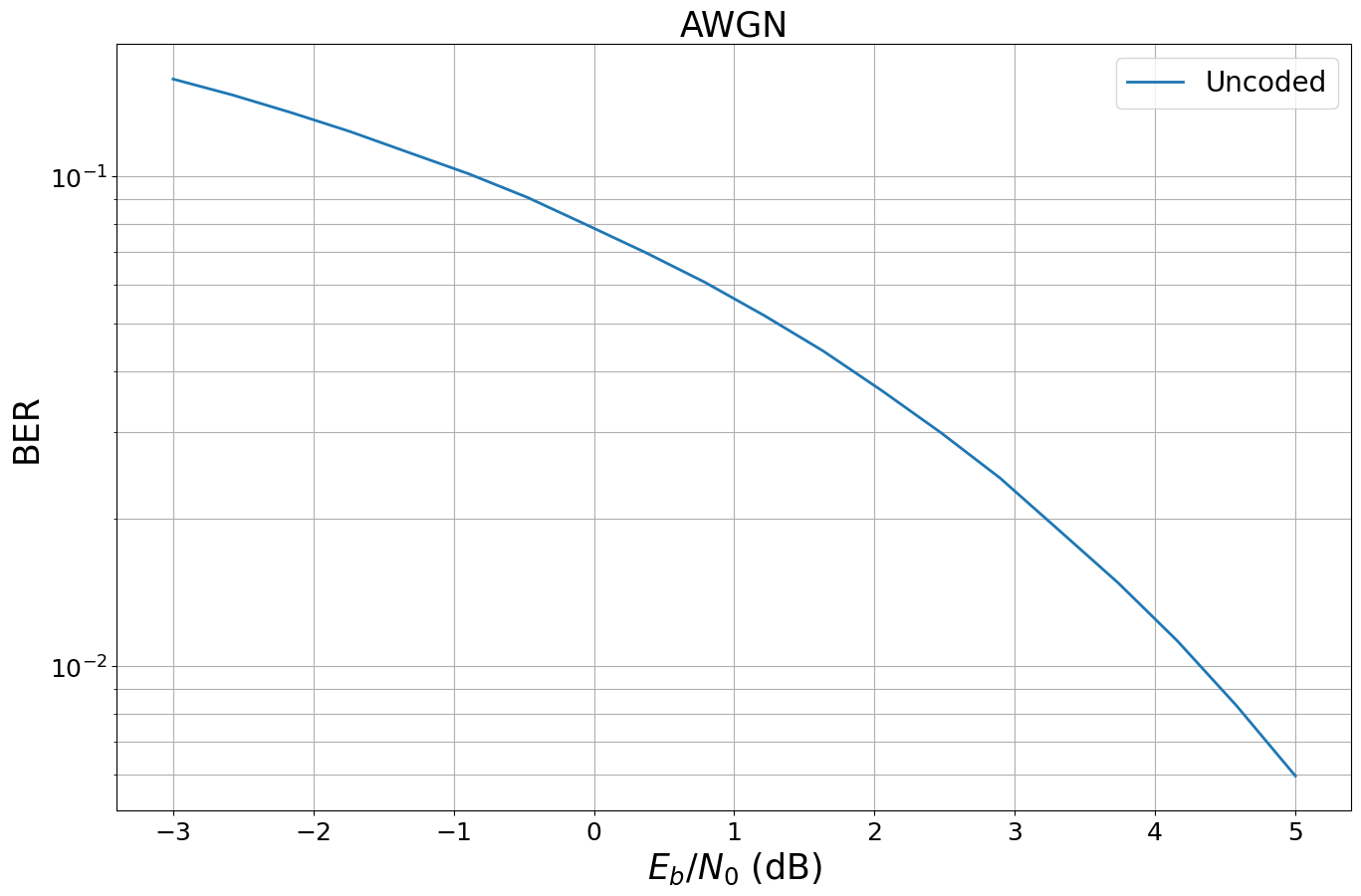
The sn.utils.PlotBER object stores the results and allows to add additional simulations to the previous curves.
Remark: In Sionna, a block error is defined to happen if for two tensors at least one position in the last dimension differs (i.e., at least one bit wrongly received per codeword). The bit error rate the total number of erroneous positions divided by the total number of transmitted bits.
Forward Error Correction (FEC)
We now add channel coding to our transceiver to make it more robust against transmission errors. For this, we will use 5G compliant low-density parity-check (LDPC) codes and Polar codes. You can find more detailed information in the notebooks Bit-Interleaved Coded Modulation (BICM) and 5G Channel Coding and Rate-Matching: Polar vs. LDPC Codes.
[16]:
k = 12
n = 20
encoder = sn.fec.ldpc.LDPC5GEncoder(k, n)
decoder = sn.fec.ldpc.LDPC5GDecoder(encoder, hard_out=True)
Let us encode some random input bits.
[17]:
BATCH_SIZE = 1 # one codeword in parallel
u = binary_source([BATCH_SIZE, k])
print("Input bits are: \n", u.numpy())
c = encoder(u)
print("Encoded bits are: \n", c.numpy())
Input bits are:
[[0. 0. 0. 0. 1. 0. 0. 1. 1. 1. 1. 1.]]
Encoded bits are:
[[1. 0. 0. 1. 1. 1. 1. 1. 0. 1. 1. 0. 1. 1. 1. 1. 0. 1. 1. 0.]]
One of the fundamental paradigms of Sionna is batch-processing. Thus, the example above could be executed for arbitrary batch-sizes to simulate batch_size codewords in parallel.
However, Sionna can do more - it supports N-dimensional input tensors and, thereby, allows the processing of multiple samples of multiple users and several antennas in a single command line. Let’s say we want to encode batch_size codewords of length n for each of the num_users connected to each of the num_basestations. This means in total we transmit batch_size * n * num_users * num_basestations bits.
[18]:
BATCH_SIZE = 10 # samples per scenario
num_basestations = 4
num_users = 5 # users per basestation
n = 1000 # codeword length per transmitted codeword
coderate = 0.5 # coderate
k = int(coderate * n) # number of info bits per codeword
# instantiate a new encoder for codewords of length n
encoder = sn.fec.ldpc.LDPC5GEncoder(k, n)
# the decoder must be linked to the encoder (to know the exact code parameters used for encoding)
decoder = sn.fec.ldpc.LDPC5GDecoder(encoder,
hard_out=True, # binary output or provide soft-estimates
return_infobits=True, # or also return (decoded) parity bits
num_iter=20, # number of decoding iterations
cn_type="boxplus-phi") # also try "minsum" decoding
# draw random bits to encode
u = binary_source([BATCH_SIZE, num_basestations, num_users, k])
print("Shape of u: ", u.shape)
# We can immediately encode u for all users, basetation and samples
# This all happens with a single line of code
c = encoder(u)
print("Shape of c: ", c.shape)
print("Total number of processed bits: ", np.prod(c.shape))
Shape of u: (10, 4, 5, 500)
Shape of c: (10, 4, 5, 1000)
Total number of processed bits: 200000
This works for arbitrary dimensions and allows a simple extension of the designed system to multi-user or multi-antenna scenarios.
Let us now replace the LDPC code by a Polar code. The API remains similar.
[19]:
k = 64
n = 128
encoder = sn.fec.polar.Polar5GEncoder(k, n)
decoder = sn.fec.polar.Polar5GDecoder(encoder,
dec_type="SCL") # you can also use "SCL"
Advanced Remark: The 5G Polar encoder/decoder class directly applies rate-matching and the additional CRC concatenation. This is all done internally and transparent to the user.
In case you want to access low-level features of the Polar codes, please use sionna.fec.polar.PolarEncoder and the desired decoder (sionna.fec.polar.PolarSCDecoder, sionna.fec.polar.PolarSCLDecoder or sionna.fec.polar.PolarBPDecoder).
Further details can be found in the tutorial notebook on 5G Channel Coding and Rate-Matching: Polar vs. LDPC Codes.

[20]:
class CodedSystemAWGN(Model): # Inherits from Keras Model
def __init__(self, num_bits_per_symbol, n, coderate):
super().__init__() # Must call the Keras model initializer
self.num_bits_per_symbol = num_bits_per_symbol
self.n = n
self.k = int(n*coderate)
self.coderate = coderate
self.constellation = sn.mapping.Constellation("qam", self.num_bits_per_symbol)
self.mapper = sn.mapping.Mapper(constellation=self.constellation)
self.demapper = sn.mapping.Demapper("app", constellation=self.constellation)
self.binary_source = sn.utils.BinarySource()
self.awgn_channel = sn.channel.AWGN()
self.encoder = sn.fec.ldpc.LDPC5GEncoder(self.k, self.n)
self.decoder = sn.fec.ldpc.LDPC5GDecoder(self.encoder, hard_out=True)
#@tf.function # activate graph execution to speed things up
def __call__(self, batch_size, ebno_db):
no = sn.utils.ebnodb2no(ebno_db, num_bits_per_symbol=self.num_bits_per_symbol, coderate=self.coderate)
bits = self.binary_source([batch_size, self.k])
codewords = self.encoder(bits)
x = self.mapper(codewords)
y = self.awgn_channel([x, no])
llr = self.demapper([y,no])
bits_hat = self.decoder(llr)
return bits, bits_hat
[21]:
CODERATE = 0.5
BATCH_SIZE = 2000
model_coded_awgn = CodedSystemAWGN(num_bits_per_symbol=NUM_BITS_PER_SYMBOL,
n=2048,
coderate=CODERATE)
ber_plots.simulate(model_coded_awgn,
ebno_dbs=np.linspace(EBN0_DB_MIN, EBN0_DB_MAX, 15),
batch_size=BATCH_SIZE,
num_target_block_errors=500,
legend="Coded",
soft_estimates=False,
max_mc_iter=15,
show_fig=True,
forward_keyboard_interrupt=False);
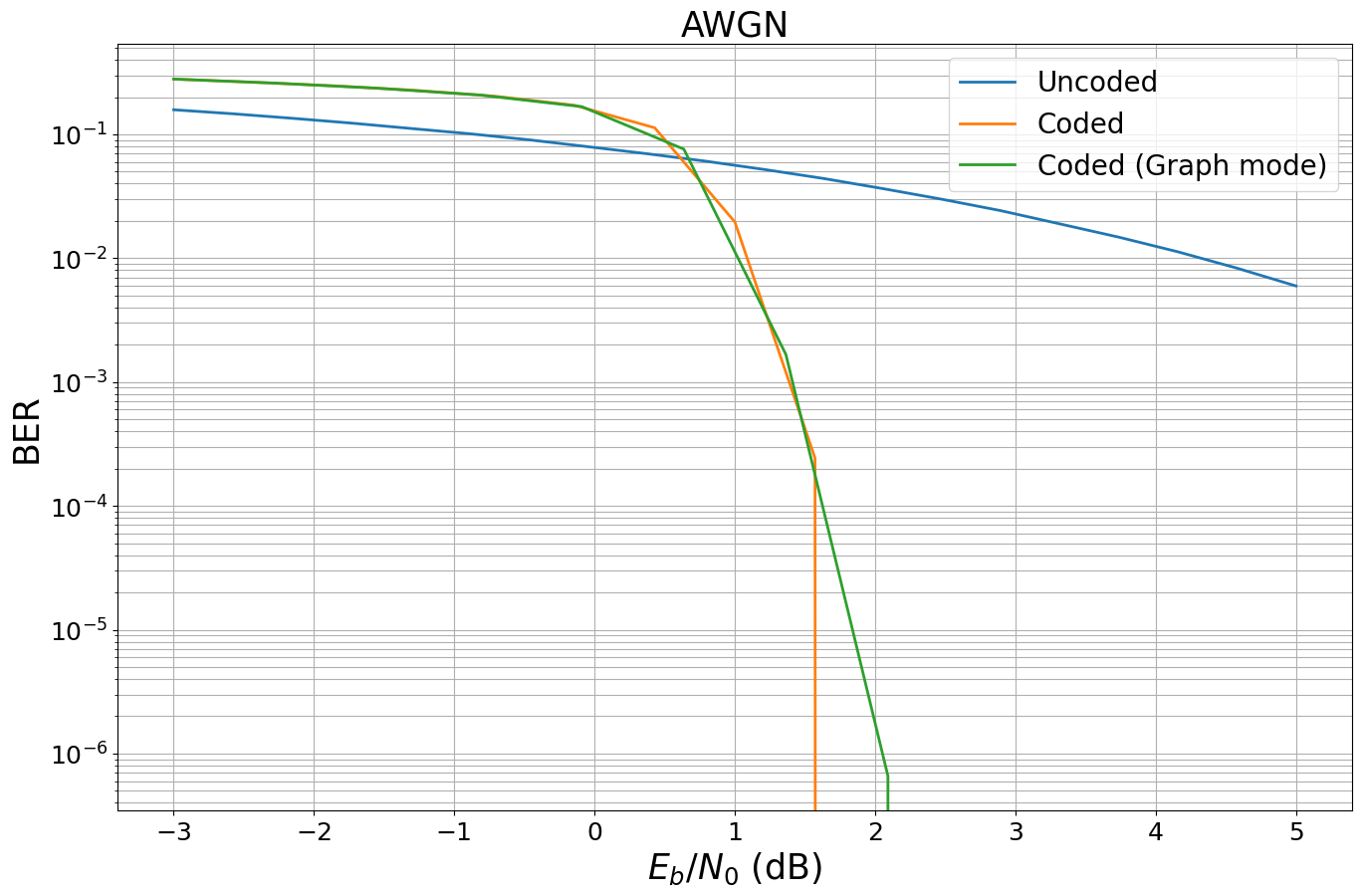
EbNo [dB] | BER | BLER | bit errors | num bits | block errors | num blocks | runtime [s] | status
---------------------------------------------------------------------------------------------------------------------------------------
-3.0 | 2.7968e-01 | 1.0000e+00 | 572778 | 2048000 | 2000 | 2000 | 0.7 |reached target block errors
-2.429 | 2.6357e-01 | 1.0000e+00 | 539792 | 2048000 | 2000 | 2000 | 0.6 |reached target block errors
-1.857 | 2.4671e-01 | 1.0000e+00 | 505261 | 2048000 | 2000 | 2000 | 0.6 |reached target block errors
-1.286 | 2.2724e-01 | 1.0000e+00 | 465395 | 2048000 | 2000 | 2000 | 0.6 |reached target block errors
-0.714 | 2.0353e-01 | 1.0000e+00 | 416826 | 2048000 | 2000 | 2000 | 0.6 |reached target block errors
-0.143 | 1.7185e-01 | 1.0000e+00 | 351951 | 2048000 | 2000 | 2000 | 0.6 |reached target block errors
0.429 | 1.1305e-01 | 9.9200e-01 | 231527 | 2048000 | 1984 | 2000 | 0.6 |reached target block errors
1.0 | 1.9613e-02 | 4.6450e-01 | 40168 | 2048000 | 929 | 2000 | 0.6 |reached target block errors
1.571 | 2.4287e-04 | 1.3533e-02 | 7461 | 30720000 | 406 | 30000 | 9.2 |reached max iter
2.143 | 0.0000e+00 | 0.0000e+00 | 0 | 30720000 | 0 | 30000 | 9.2 |reached max iter
Simulation stopped as no error occurred @ EbNo = 2.1 dB.
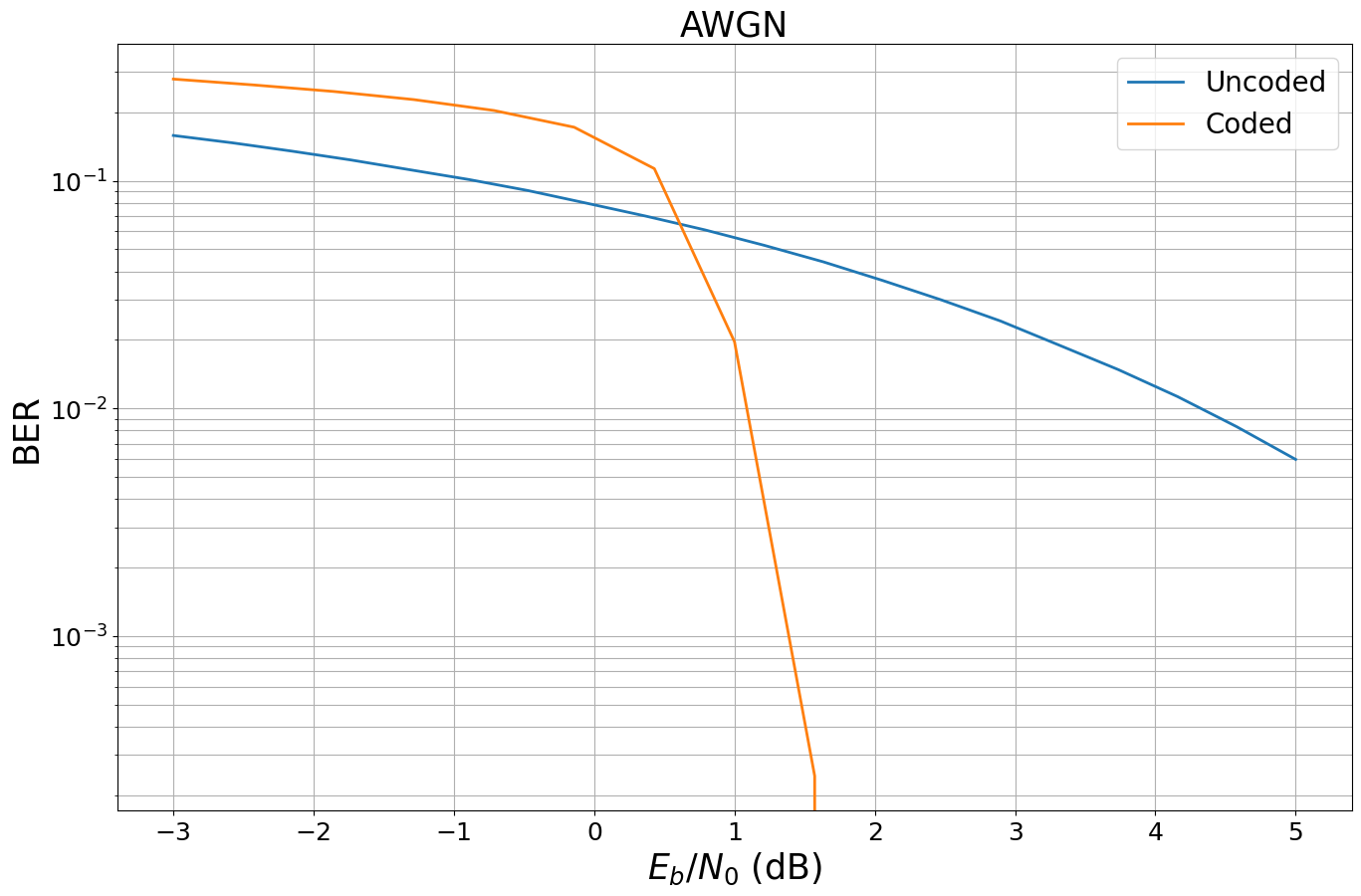
As can be seen, the BerPlot class uses multiple stopping conditions and stops the simulation after no error occured at a specifc SNR point.
Task: Replace the coding scheme by a Polar encoder/decoder or a convolutional code with Viterbi decoding.
Eager vs Graph Mode
So far, we have executed the example in eager mode. This allows to run TensorFlow ops as if it was written NumPy and simplifies development and debugging.
However, to unleash Sionna’s full performance, we need to activate graph mode which can be enabled with the function decorator @tf.function().
We refer to TensorFlow Functions for further details.
[22]:
@tf.function() # enables graph-mode of the following function
def run_graph(batch_size, ebno_db):
# all code inside this function will be executed in graph mode, also calls of other functions
print(f"Tracing run_graph for values batch_size={batch_size} and ebno_db={ebno_db}.") # print whenever this function is traced
return model_coded_awgn(batch_size, ebno_db)
[23]:
batch_size = 10 # try also different batch sizes
ebno_db = 1.5
# run twice - how does the output change?
run_graph(batch_size, ebno_db)
Tracing run_graph for values batch_size=10 and ebno_db=1.5.
[23]:
(<tf.Tensor: shape=(10, 1024), dtype=float32, numpy=
array([[0., 0., 0., ..., 1., 0., 1.],
[0., 1., 1., ..., 0., 0., 0.],
[1., 1., 0., ..., 0., 0., 1.],
...,
[0., 1., 0., ..., 1., 1., 1.],
[1., 1., 1., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 1., 0.]], dtype=float32)>,
<tf.Tensor: shape=(10, 1024), dtype=float32, numpy=
array([[0., 0., 0., ..., 1., 0., 1.],
[0., 1., 1., ..., 0., 0., 0.],
[1., 1., 0., ..., 0., 0., 1.],
...,
[0., 1., 0., ..., 1., 1., 1.],
[1., 1., 1., ..., 0., 0., 0.],
[0., 0., 0., ..., 1., 1., 0.]], dtype=float32)>)
In graph mode, Python code (i.e., non-TensorFlow code) is only executed whenever the function is traced. This happens whenever the input signature changes.
As can be seen above, the print statement was executed, i.e., the graph was traced again.
To avoid this re-tracing for different inputs, we now input tensors. You can see that the function is now traced once for input tensors of same dtype.
See TensorFlow Rules of Tracing for details.
Task: change the code above such that tensors are used as input and execute the code with different input values. Understand when re-tracing happens.
Remark: if the input to a function is a tensor its signature must change and not just its value. For example the input could have a different size or datatype. For efficient code execution, we usually want to avoid re-tracing of the code if not required.
[24]:
# You can print the cached signatures with
print(run_graph.pretty_printed_concrete_signatures())
run_graph(batch_size=10, ebno_db=1.5)
Returns:
(<1>, <2>)
<1>: float32 Tensor, shape=(10, 1024)
<2>: float32 Tensor, shape=(10, 1024)
We now compare the throughput of the different modes.
[25]:
repetitions = 4 # average over multiple runs
batch_size = BATCH_SIZE # try also different batch sizes
ebno_db = 1.5
# --- eager mode ---
t_start = time.perf_counter()
for _ in range(repetitions):
bits, bits_hat = model_coded_awgn(tf.constant(batch_size, tf.int32),
tf.constant(ebno_db, tf. float32))
t_stop = time.perf_counter()
# throughput in bit/s
throughput_eager = np.size(bits.numpy())*repetitions / (t_stop - t_start) / 1e6
print(f"Throughput in Eager mode: {throughput_eager :.3f} Mbit/s")
# --- graph mode ---
# run once to trace graph (ignored for throughput)
run_graph(tf.constant(batch_size, tf.int32),
tf.constant(ebno_db, tf. float32))
t_start = time.perf_counter()
for _ in range(repetitions):
bits, bits_hat = run_graph(tf.constant(batch_size, tf.int32),
tf.constant(ebno_db, tf. float32))
t_stop = time.perf_counter()
# throughput in bit/s
throughput_graph = np.size(bits.numpy())*repetitions / (t_stop - t_start) / 1e6
print(f"Throughput in graph mode: {throughput_graph :.3f} Mbit/s")
Throughput in Eager mode: 3.130 Mbit/s
Tracing run_graph for values batch_size=Tensor("batch_size:0", shape=(), dtype=int32) and ebno_db=Tensor("ebno_db:0", shape=(), dtype=float32).
Throughput in graph mode: 14.483 Mbit/s
Let’s run the same simulation as above in graph mode.
[26]:
ber_plots.simulate(run_graph,
ebno_dbs=np.linspace(EBN0_DB_MIN, EBN0_DB_MAX, 12),
batch_size=BATCH_SIZE,
num_target_block_errors=500,
legend="Coded (Graph mode)",
soft_estimates=True,
max_mc_iter=100,
show_fig=True,
forward_keyboard_interrupt=False);
EbNo [dB] | BER | BLER | bit errors | num bits | block errors | num blocks | runtime [s] | status
---------------------------------------------------------------------------------------------------------------------------------------
-3.0 | 2.7972e-01 | 1.0000e+00 | 572860 | 2048000 | 2000 | 2000 | 0.2 |reached target block errors
-2.273 | 2.5935e-01 | 1.0000e+00 | 531157 | 2048000 | 2000 | 2000 | 0.2 |reached target block errors
-1.545 | 2.3590e-01 | 1.0000e+00 | 483122 | 2048000 | 2000 | 2000 | 0.1 |reached target block errors
-0.818 | 2.0800e-01 | 1.0000e+00 | 425979 | 2048000 | 2000 | 2000 | 0.2 |reached target block errors
-0.091 | 1.6746e-01 | 1.0000e+00 | 342949 | 2048000 | 2000 | 2000 | 0.2 |reached target block errors
0.636 | 7.5977e-02 | 9.1400e-01 | 155600 | 2048000 | 1828 | 2000 | 0.2 |reached target block errors
1.364 | 1.6699e-03 | 7.1250e-02 | 13680 | 8192000 | 570 | 8000 | 0.6 |reached target block errors
2.091 | 6.5918e-07 | 4.0000e-05 | 135 | 204800000 | 8 | 200000 | 15.0 |reached max iter
2.818 | 0.0000e+00 | 0.0000e+00 | 0 | 204800000 | 0 | 200000 | 14.9 |reached max iter
Simulation stopped as no error occurred @ EbNo = 2.8 dB.
Task: TensorFlow allows to compile graphs with XLA. Try to further accelerate the code with XLA (@tf.function(jit_compile=True)).
Remark: XLA is still an experimental feature and not all TensorFlow (and, thus, Sionna) functions support XLA.
Task 2: Check the GPU load with !nvidia-smi. Find the best tradeoff between batch-size and throughput for your specific GPU architecture.
Exercise
Simulate the coded bit error rate (BER) for a Polar coded and 64-QAM modulation. Assume a codeword length of n = 200 and coderate = 0.5.
Hint: For Polar codes, successive cancellation list decoding (SCL) gives the best BER performance. However, successive cancellation (SC) decoding (without a list) is less complex.
[27]:
n = 200
coderate = 0.5
# *You can implement your code here*