Integration of a Neural Demapper#
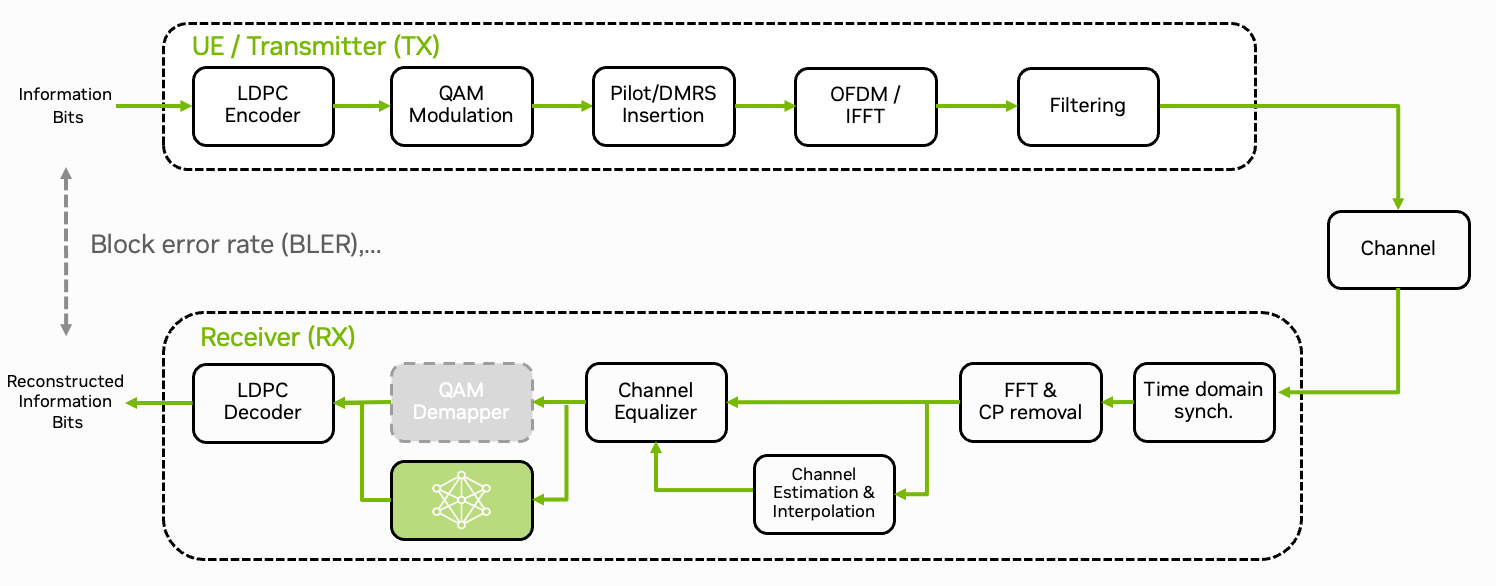
In this tutorial, we will integrate a neural network-based demapper into the signal processing pipeline of the physical uplink shared channel (PUSCH). We use NVIDIA TensorRT for the accelerated inference and train the neural network using Sionna. Further, training with real world data can be realized by leveraging the previous Plugins & Data Acquisition tutorial; for label recovery using error-correcting codes see [Schibisch2018].
Note that the main purpose of this tutorial is to show the efficient integration of neural components into the 5G stack. The block error-rate performance gains are not significant for this simple example. However, similar to the GPU-Accelerated LDPC Decoding tutorial, the integration requires careful consideration of the memory transfer patterns between the CPU and the GPU to keep the latency as low as possible.
In this tutorial, you will learn:
How to export the trained model from Sionna to TensorRT
How to integrate the TensorRT engine into the 5G stack
CUDA graphs for latency reductions
The tutorial is split into two parts:
References#
R. Gadiyar, L. Kundu, J. Boccuzzi, “Building Software-Defined, High-Performance, and Efficient vRAN Requires Programmable Inline Acceleration” NVIDIA Developer Blog, 2023.
L. Kundu, et al., “Hardware Acceleration for Open Radio Access Networks: A Contemporary Overview,” IEEE Communications Magazine, vol. 62, no. 9, pp. 160-167, 2023.
S. Schibisch et al., “Online Label Recovery for Deep Learning-based Communication through Error Correcting Codes,” IEEE ISWCS, 2018.